 en Honduras en 2020. Imagen: contiene datos modificados de Copernicus Sentinel (2020), procesados por UN-SPIDER.")
El aprendizaje automático ofrece nuevas posibilidades para la detección de inundaciones gracias a la disponibilidad de más datos, el aumento de la potencia de cálculo y la mejora de los algoritmos de aprendizaje automático. El aprendizaje automático se ha impuesto como el instrumento favorito para profundizar en los sistemas no lineales y generar pronósticos de inundaciones. En el pronóstico de inundaciones, los métodos tradicionales de predicción de variables de riesgo pueden implicar una cadena de modelos hidrológicos e hidráulicos que describen los procesos físicos. Aunque esos modelos permiten la comprensión del sistema, a menudo tienen elevados requisitos computacionales y de datos. Los métodos de aprendizaje automático tienen el potencial de mejorar la precisión, así como de reducir el tiempo de cálculo y el coste de desarrollo de los modelos.
Tabla de Contenido
1. ¿Qué es el Aprendizaje Automático?
1.1 Clasificación de las Tareas del Aprendizaje Automático
1.1.2 Aprendizaje No Supervisado
2. Limitaciones de los Métodos Convencionales
3. Aprendizaje Automático para la Detección de Inundaciones
3.1. Macrodatos para la Gestión de Inundaciones
3.2. ¿Qué se está haciendo actualmente?
3.2.1. Detección y Mapeo de Inundaciones Utilizando Datos de Observación Terrestre
3.2.2. Predicción y Modelización de Inundaciones
3.3. Algoritmos Comunes de Aprendizaje Automático
3.3.1. Redes Neuronales Artificiales (RNAs)
3.3.2. Sistema Adaptativo de Inferencia Neuro-Difusa (ANFIS)
3.3.3. Árboles de Decisión (DT)
3.3.4. Sistemas de Predicción de Conjuntos (EPSs)
3.3.5. Máquina de Vectores de Apoyo (SVM)
1. ¿Qué es el Aprendizaje Automático?
El aprendizaje automático (ML, por sus siglas en inglés) es un campo de la inteligencia artificial (IA) que se utiliza para reconocer patrones de forma automática e intuitiva en un conjunto de datos sin necesidad de programación explícita. De este modo, el ML ofrece una mayor facilidad de resolución de problemas complejos con un bajo coste computacional, así como un rápido entrenamiento, validación, prueba y evaluación, alto rendimiento en comparación con los modelos físicos y una complejidad relativamente menor (Mosavi et al., 2018; Wagenaar et al., 2020). La Figura 1 ilustra los pasos básicos necesarios para construir un modelo ML.

1.1. Clasificación de las Tareas del Aprendizaje Automático
La mayoría de los problemas de aprendizaje estadístico pertenecen a una de estas dos categorías: (i) aprendizaje supervisado, y (ii) aprendizaje no supervisado.
1.1.1. Aprendizaje Supervisado
El aprendizaje supervisado puede aplicar lo aprendido en el pasado a los datos nuevos utilizando ejemplos etiquetados para predecir acontecimientos futuros. En otras palabras, el objetivo es establecer un modelo que relacione la respuesta con los predictores y prediga con precisión la respuesta para futuras observaciones ("predicción") o comprenda mejor la relación entre la respuesta y los predictores ("inferencia"). A partir del análisis de un grupo de datos de prueba conocido, el algoritmo de aprendizaje produce una función inferida para realizar predicciones sobre los resultados (Casella et al., 2006). El sistema de aprendizaje supervisado puede proporcionar resultados para cualquier nuevo dato después de un periodo de entrenamiento suficiente. El algoritmo de aprendizaje también puede comparar su resultado con el resultado correcto y detectar errores para modificar así el modelo. Muchos métodos clásicos de aprendizaje estadístico, como la regresión lineal y la regresión logística, así como enfoques más modernos, como el boosting y las Máquinas de Vectores de Soporte, operan en el ámbito del aprendizaje supervisado. Un algoritmo de aprendizaje basado en datos de entrada o características se entrena a sí mismo en una o varias funciones que pueden utilizarse posteriormente para inferir el resultado o las etiquetas. El entrenamiento se realiza con las etiquetas correctas, de modo que el algoritmo se ajusta a sí mismo con la sintonización de hiperparámetros, que son los más importantes para controlar el comportamiento y la predicción correcta. El entrenamiento se detiene cuando se alcanza un nivel de rendimiento aceptable (Liu y Wu, 2012).
1.1.2. Aprendizaje No Supervisado
Por el contrario, el aprendizaje no supervisado se refiere a una situación en la que cada observación tiene predictores sin valor de respuesta asociado que puedan utilizarse para supervisar el análisis. En este caso, el modelo trabaja en cierto modo a ciegas, ya que no se proporcionan etiquetas al algoritmo de aprendizaje, por lo que éste debe encontrar por sí mismo la estructura de los datos de entrada. El aprendizaje no supervisado puede utilizarse para descubrir patrones ocultos en los datos y comprender las relaciones entre las variables o las observaciones. Una herramienta de aprendizaje estadístico que se utiliza a menudo es el análisis de conglomerados (Casella et al., 2006).
2. Limitaciones de los Métodos Convencionales
Las inundaciones figuran entre los desastres naturales más destructivos y representan casi la mitad de los desastres naturales, afectando a 2.300 millones de personas. La mejora de la respuesta para mitigar y gestionar el riesgo de inundaciones puede verse muy favorecida por la observación satelital, que puede utilizarse en las fases de mitigación, respuesta y recuperación del ciclo de desastres (IPCC, 2012). Los métodos convencionales para mapear inundaciones utilizan sensores de satélite ópticos y de radar con diferentes resoluciones espaciales y frecuencias temporales. Métodos como la umbralización de bandas (band thresholding), la diferenciación normalizada, combinaciones complejas de infrarrojos de onda corta (SWIR, por sus siglas en inglés) con otras bandas, y la detección de la absorción de agua basada en pixeles en el espectro SWIR son utilizadas para detectar, mapear y monitorear inundaciones en imágenes ópticas. El espectro radiómetro de imágenes de media resolución (MODIS) aprovecha las capacidades de alta absorción del agua en el SWIR en relación con otros objetos o utiliza el espectro del infrarrojo cercano (NIR) en relación con el espectro visible. De este modo, se consigue la detección de agua a nivel global en un plazo diario. Los sensores de resolución media, como Landsat y Sentinel-2, se utilizan a menudo para identificar inundaciones mediante la umbralización de bandas, diferenciación normalizada o combinaciones más complejas de SWIR y NIR con otras bandas. El principal inconveniente del uso de estas técnicas para la detección de inundaciones es que presentan fallos en la clasificación del agua y de las sombras de las nubes, que tienen valores bajos de reflectancia en SWIR y NIR (Bonafilia et al., 2020).
Los radares de apertura sintética (SAR) pueden ser importantes para la detección de inundaciones debido a su capacidad para penetrar a través de las nubes. Los sensores SAR, como Sentinel-1, se han utilizado para mapear inundaciones mediante la identificación de agua, que normalmente tiene valores de retrodispersión más bajos en relación con otras características (en las bandas VV, HH, VH y HV) (Mosavi et al., 2018). El agua se identifica mediante el umbral de los valores de retrodispersión en una sola imagen, la diferencia de retrodispersión entre dos imágenes o la varianza de la retrodispersión en una serie temporal. La vegetación inundada y las inundaciones en zonas urbanas pueden presentar un aumento de la retrodispersión durante las inundaciones debido a un efecto de "doble rebote" (Huang et al., 2018). Los daños por inundaciones urbanas se han estimado utilizando la pérdida de coherencia de la señal interferométrica (información de fase) de los sensores SAR entre dos periodos de tiempo (Rubinato et al., 2019). Sin embargo, casi todos estos métodos se basan en umbrales para determinar las zonas inundadas frente a las no inundadas. Es más, los resultados derivados de la umbralización a menudo sobrestiman o subestiman las áreas inundadas porque no existen directrices estándar para determinar los valores umbral, por lo tanto, es definido por el usuario (Bonafilia et al., 2020).
Los modelos basados en física se utilizan desde hace tiempo para predecir fenómenos hidrológicos, como las precipitaciones torrenciales / escorrentía en aguas poco profundas, modelos hidráulicos de flujo y otros fenómenos de circulación global, incluidos los efectos vinculados de la atmósfera, el océano y las inundaciones. Aunque los modelos físicos muestran grandes capacidades para predecir una amplia gama de escenarios de inundaciones, a menudo requieren varios tipos de datos de seguimiento hidro-geomorfológico, por lo que exigen un cálculo intensivo, lo que impide predecir las inundaciones a corto plazo. Además, el desarrollo de modelos basados en la física a menudo requiere un profundo conocimiento y experiencia en relación con los parámetros hidrológicos y no son fiables debido a los errores sistemáticos inherentes (Mosavi et al., 2018).
3. Aprendizaje Automático para la Detección de Inundaciones
La creciente disponibilidad de información, junto con el aumento de la potencia de cálculo y la mejora de los algoritmos de ML para su análisis, está provocando cambios en casi todos los aspectos de nuestras vidas. Se espera que esta tendencia continúe a medida que se disponga de más datos, aumente la potencia informática y mejoren los algoritmos de ML. Las evaluaciones del riesgo y el impacto de las inundaciones también se están viendo influidas por esta tendencia, sobre todo en ámbitos como el desarrollo de medidas de mitigación, la preparación de respuestas de emergencia y la planificación de planes de recuperación tras las inundaciones ( Lamovec et al., 2013; Bonafilia et al., 2020; Wagenaar et al., 2020).
Con los avances informáticos y la mejora de los algoritmos, el ML se ha convertido en el instrumento preferido para profundizar en los sistemas no lineales y explorar las predicciones de inundaciones generadas automáticamente. Algoritmos informáticos como las redes neuronales se han utilizado sobre todo para estimar las inundaciones en zonas amenazadas de un río y sus efectos fuera de esa zona concreta. Se prevé que en el futuro sean más las aplicaciones viables y que muchos modelos de procesos y métodos de observación tradicionales sean sustituidos por el ML. Ejemplos de ello son el uso de ML en datos de teledetección para estimar la exposición o en datos de redes sociales para mejorar la respuesta a las inundaciones. Algunas mejoras pueden requerir nuevos esfuerzos de recopilación de datos, como en el caso de la modelización de daños por inundaciones o fallos en las defensas (Zehra, 2020).
3.1. Macrodatos para la Gestión de Inundaciones
Los macrodatos (Big Data) han evolucionado a un ritmo increíblemente rápido. En el contexto específico de la resiliencia ante los desastres, los macrodatos pueden ayudar en las cuatro fases de la gestión de desastres: prevención, preparación, respuesta y recuperación. Este impulso de los nuevos datos combinado con los algoritmos de aprendizaje automático podría dar lugar a cambios en la evaluación del riesgo y el impacto de las inundaciones (Wagenaar et al., 2020). Asimismo, los macrodatos permiten el análisis descriptivo (análisis del estado actual o pasado de las inundaciones), el análisis predictivo (evaluación analítica de la previsión a largo plazo o a corto plazo de las inundaciones), el análisis prescriptivo y discursivo que aborda las lagunas en los flujos de información en situaciones previas, de respuesta y posteriores a los desastres (Lamovec et al., 2013). Los datos procedentes de las tecnologías emergentes, incluidas las imágenes por satélite, las imágenes aéreas y los vídeos de vehículos aéreos no tripulados (UAV), la red de sensores y el Internet de las cosas (IoT), la detección y el alcance de la luz (LiDAR) aérea y terrestre, la simulación, los datos espaciales, el crowdsourcing, las redes sociales y el GPS móvil y los registros de datos de llamadas (CDR) forman el núcleo de los macrodatos para las inundaciones y otros desastres (Lee et al., 2012).

3.2. ¿Qué se está haciendo actualmente?
Para crear un modelo de predicción ML, se suelen utilizar los registros históricos de inundaciones, además de los datos acumulados en tiempo real de varios pluviómetros u otros dispositivos de detección para diversos periodos de retorno. Las fuentes del conjunto de datos son tradicionalmente las precipitaciones y el nivel del agua, medidos por pluviómetros terrestres o por tecnologías de teledetección relativamente nuevas, como satélites, sistemas multisensoriales o radares (Seo y Kim, 2016).
3.2.1. Detección y Mapeo de Inundaciones Utilizando Datos de Observación Terrestre
Veljanovski et al., 2011 realizaron una comparación de la delineación de agua basada en píxeles, la clasificación basada en objetos y el procedimiento ML. La aplicación del procedimiento ML para la determinación de áreas inundadas es diferente de los otros dos métodos mencionados anteriormente, ya que utiliza un conjunto más amplio de datos auxiliares. Además de utilizar las imágenes obtenidas por radar y los derivados del Modelo de Elevación Digital (pendiente, alturas), para modelizar las zonas inundadas, se utilizaron datos hidrológicos (distancia a las corrientes de agua) y de uso del suelo. El enfoque ML demostró su eficacia en la detección de inundaciones bajo los maizales, donde las ondas de radar no penetran a través del cultivo hasta los terrenos inundados, algo en lo que fallaron los otros dos métodos.
En este estudio, el procedimiento de ML se llevó a cabo mediante los siguientes pasos. Preparación de un conjunto significativo de datos de entrenamiento: se generaron 300 puntos de entrenamiento para representar un área de 25 × 20 km de ancho. Cada uno de estos puntos se describió mediante seis atributos: valor del píxel de la imagen de radar (intensidad), altura, pendiente, distancia respecto al agua (ríos y arroyos permanentes), uso del suelo y etiqueta "inundado" con sólo dos valores permitidos: 0 para zonas no inundadas y 1 para zonas inundadas.
Shahabi et al., 2020 propusieron una nueva técnica de mapeo de la susceptibilidad a las inundaciones utilizando modelos de conjunto basados en bagging y k-Vecinos más Cercanos ("K-Nearest Neighbour", KNN, por sus siglas en inglés). El objetivo era crear mapas que pudieran ser utilizados por los responsables de la toma de decisiones y los gestores de riesgos para reducir las lesiones y los daños a las infraestructuras causados por las inundaciones utilizando datos de radar Sentinel-1 y varios factores condicionantes de las inundaciones (elevación, pendiente, curvatura, índice de potencia de la corriente, índice de humedad topográfica, litología, precipitaciones, uso del suelo/cobertura del suelo, densidad del río y distancia al río). El modelo con mejores resultados fue el modelo híbrido inteligente (Bagging Tree-Cubic KNN), que es una combinación de una técnica de ensemble bagging y las cuatro funciones del clasificador KNN. Se utilizó la relación de ganancia de información (Information Gain Ratio, IGR, por sus siglas en inglés) en los diez factores condicionantes de la inundación y se demostró que, aunque todos los factores son significativos en el entrenamiento del modelo, la distancia al río destacó como el factor más importante, seguido de la pendiente de la ladera y la curvatura.
Peter et al., 2013 estudiaron la detección de inundaciones mediante técnicas de ML como alternativa a métodos más convencionales para el mapeo rápido de inundaciones. Se han realizado mejoras significativas en las evaluaciones en tiempo casi real de las inundaciones debido al aumento de las tasas de adquisición de datos, la mayor resolución de los sensores, la mejora de los algoritmos de detección de cambios y la integración de los sistemas de teledetección. Sin embargo, los desastres naturales nunca serán completamente predecibles. En tales situaciones, los equipos de rescate necesitan conocer la situación actual sobre el terreno y esta información se aprovecha mejor si la zona afectada se mapea en tiempo real. El estudio concluye que el ML garantiza un mapeo rápido y preciso. Los datos utilizados fueron imágenes ópticas de satélite (SPOT 5), modelos digitales del terreno (MDT) y la red fluvial, y el resultado fue un modelo de clasificación para detectar las zonas inundadas. Los índices de diferencia normalizados (NDVI, NDBI y NBI) se calcularon a partir de la imagen óptica y se introdujeron como predictores en los algoritmos de clasificación (Naïve Bayes, Bayes Net, J48, Random Tree y Random Forest). Los resultados demostraron que los algoritmos de ML podían utilizarse para detectar zonas inundadas con gran precisión, lo cual sólo puede conseguirse utilizando tanto datos de buena calidad así como un algoritmo ML eficaz.
Los datos para entrenar el modelo son el obstáculo más común a la hora de utilizar algoritmos de ML para la detección de inundaciones. Bonafilia et al. (2020) intentaron abordar este obstáculo proporcionando el conjunto de datos Sen1Floods11. El estudio pretende contribuir a los esfuerzos para hacer operativos los algoritmos de aprendizaje automático para el mapeo de inundaciones a escala global. Sen1Floods11 es un conjunto de datos de aguas superficiales que incluye imágenes Sentinel-1 sin procesar y agua permanente y agua de inundación clasificadas. Este conjunto de datos consta de 4.831 chips de 512x512 que cubren 120.406 km2 y abarca los 14 biomas, 357 ecorregiones y 6 continentes del mundo a través de 11 eventos de inundación. El conjunto de datos se utilizó para entrenar, validar y probar redes neuronales totalmente convolucionales (FCNN) para segmentar el agua permanente y el agua de las inundaciones. El conjunto de datos Sen1Floods11 consta de cuatro subconjuntos: i) 446 chips etiquetados a mano de aguas superficiales procedentes de inundaciones; ii) 814 chips de etiquetas de datos de aguas permanentes disponibles públicamente procedentes de Landsat (conjunto de datos de aguas superficiales del CCI); iii) 4.385 chips de aguas superficiales clasificadas a partir de imágenes de Sentinel-2 procedentes de inundaciones y iv) 4.385 chips de aguas superficiales clasificadas a partir de imágenes de Sentinel-1 procedentes de inundaciones. Este método se comparó con el método habitual de teledetección consistente en umbralizar la retrodispersión del radar para identificar las aguas superficiales. Los resultados muestran que el modelo FCNN entrenado en clasificaciones de eventos de inundaciones de Sentinel-2 tiene el mejor rendimiento para identificar inundaciones y agua superficial total, mientras que el umbral de retrodispersión dio el mejor resultado para identificar solo clases de agua permanente. Esto sugiere que los modelos de aprendizaje automático para la detección de inundaciones utilizando datos de radar pueden superar a las técnicas de teledetección basadas en umbrales y funcionar mejor con etiquetas de entrenamiento que incluyan específicamente agua de inundación, no solo agua superficial permanente. El código fuente del proyecto Sen1Floods11 puede consultarse aquí.

3.2.2. Predicción y Modelización de Inundaciones
En comparación con los modelos estadísticos tradicionales, los modelos ML se utilizaron para la predicción con mayor precisión. Ortiz-García et al. (2014) describieron cómo las técnicas de ML podían modelizar eficazmente sistemas hidrológicos complejos como las inundaciones. Muchos algoritmos de ML, por ejemplo, redes neuronales artificiales (ANN), neuro-difusa, máquina de vectores soporte (SVM), y regresión de vectores soporte (SVR), fueron reportados como efectivos para el pronóstico de inundaciones tanto a corto como a largo plazo. Además, se demostró que el rendimiento del ML podía mejorarse mediante la hibridación con otros métodos de ML, técnicas de soft computing, simulaciones numéricas y/o modelos físicos. Tales aplicaciones proporcionaron modelos más robustos y eficientes que pueden aprender eficazmente sistemas de inundación complejos de manera adaptativa (Mosavi et al., 2018).
3.3. Algoritmos comunes de aprendizaje automático
La Figura 2 describe los algoritmos de ML más utilizados encontrados en la literatura para la detección, predicción y modelización de inundaciones según Mosavi et al., (2018). A continuación se describen algunos de los algoritmos.
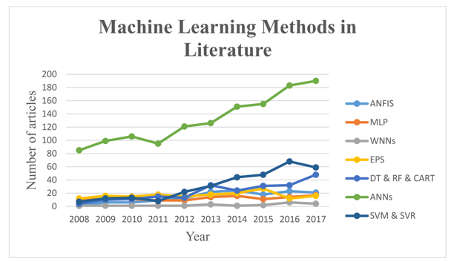
Figura 2: Principales métodos de ML utilizados para la predicción de inundaciones en la literatura (2008-2017) (Mosavi et al., 2018).
3.3.1. Redes Neuronales Artificiales (RNAs)
Las RNA son sistemas eficientes de modelización matemática con un eficaz procesamiento paralelo, lo que les permite imitar la red neuronal biológica mediante unidades neuronales interconectadas. Entre todos los métodos de ML, las RNA son los algoritmos de aprendizaje más populares, conocidos por ser versátiles y eficientes a la hora de modelar procesos complejos de inundación con una alta tolerancia a los fallos y una aproximación precisa. Así pues, las RNA se consideran herramientas fiables basadas en datos para construir modelos de caja negra de relaciones complejas y no lineales de precipitaciones e inundaciones, así como para la previsión de caudales y descargas fluviales. Las RNA ya se han utilizado con éxito en numerosas aplicaciones de predicción de crecidas, por ejemplo, predicción de caudales, caudales fluviales, modelización de lluvia-escorrentía, precipitación-escorrentía, calidad del agua, evaporación, predicción de etapas fluviales, estimación de caudales bajos, cartografía y susceptibilidad de crecidas y series temporales fluviales. Uno de los principales inconvenientes de las RNA es la necesidad de repetir el ajuste de los parámetros.
3.3.2. Sistema Adaptativo de Inferencia Neuro-Difusa (ANFIS)
La lógica difusa es un esquema de modelización cualitativa con una técnica de soft computing que utiliza el lenguaje natural. La lógica difusa es un modelo matemático simplificado, que funciona incorporando el conocimiento experto a un sistema de inferencia difusa (FIS). ANFIS imita además el aprendizaje humano mediante una función de aproximación de menor complejidad, lo que ofrece un gran potencial para la modelización no lineal de fenómenos hidrológicos extremos, en particular las inundaciones. Debido a su rápida y sencilla implementación, su aprendizaje preciso y su gran capacidad de generalización, ANFIS se ha hecho muy popular en la modelización de inundaciones.
3.3.3. Árboles de Decisión (DT)
El DT es uno de los contribuidores en la modelización predictiva con una amplia aplicación en la simulación de inundaciones. DT utiliza un árbol de decisiones desde las ramas hasta los valores objetivo de las hojas. En los árboles de clasificación (CT), las variables finales en un DT contienen un conjunto discreto de valores donde las hojas representan etiquetas de clase y las ramas representan conjunciones de etiquetas de características. Cuando la variable objetivo de un DT tiene valores continuos y se trata de un conjunto de árboles, se denomina árbol de regresión (TR). Los árboles de regresión y clasificación comparten algunas similitudes y diferencias. Como los DT se clasifican como algoritmos rápidos, se hicieron muy populares en conjuntos para modelar y predecir inundaciones. El método de bosques aleatorios (RF) es otro método de DT popular para la predicción de inundaciones. RF incluye varios árboles de predicción. Cada árbol crea un conjunto de valores predictores de respuesta asociados a un conjunto de valores independientes. Además, un conjunto de estos árboles selecciona la mejor elección de clases.
3.3.4. Sistemas de Predicción de Conjuntos (EPS)
Los conjuntos de ML consisten en un conjunto finito de modelos alternativos, que suelen permitir más flexibilidad que los alternativos. En los últimos años, los sistemas de predicción de conjuntos (EPS) se han propuesto como sistemas de predicción eficientes para proporcionar un conjunto de N predicciones. En los EPS, N es el número de realizaciones independientes de la distribución de probabilidad de un modelo. Los modelos EPS suelen utilizar múltiples algoritmos ML para proporcionar un mayor rendimiento mediante un sistema automatizado de evaluación y ponderación. Este procedimiento de ponderación se lleva a cabo para acelerar el proceso de evaluación del rendimiento. La ventaja del EPS es la gestión oportuna y automatizada y la evaluación del rendimiento de los algoritmos de conjuntos. Por lo tanto, el rendimiento de los EPS, para la modelización de inundaciones, puede mejorarse. Los EPS pueden utilizar múltiples algoritmos de aprendizaje rápido o estadísticos como conjuntos de clasificadores, por ejemplo, RNA, MLP, DT, bootstrap de bosque de rotación (RF) y boosting, lo que permite una mayor precisión y robustez. Los subsiguientes sistemas de predicción de conjuntos pueden utilizarse para cuantificar la probabilidad de inundaciones, basándose en el índice de predicción utilizado en el suceso. Por lo tanto, la calidad de los conjuntos ML puede calcularse basándose en la verificación de la distribución de probabilidades.
3.3.5. Máquina de Vectores de Apoyo (SVM)
La SVM es muy popular en la modelización de inundaciones; es una máquina de aprendizaje supervisado que funciona basándose en la teoría del aprendizaje estadístico y en la regla de minimización del riesgo estructural. El algoritmo de entrenamiento de SVM construye modelos que asignan nuevos clasificadores lineales binarios no probabilísticos, que minimizan el error empírico de clasificación y maximizan el margen geométrico mediante la resolución inversa del problema. La SVM se utiliza para predecir una cantidad hacia adelante en el tiempo basándose en el entrenamiento a partir de datos pasados. Las SVM son hoy conocidas como algoritmos ML robustos y eficientes en la predicción de inundaciones. SVM y SVR surgieron como métodos ML alternativos a las RNA, con gran popularidad entre los hidrólogos para la predicción de inundaciones. Así, se aplican en numerosos casos de predicción de inundaciones con resultados prometedores, excelente capacidad de generalización, y mejor rendimiento, en comparación con las RNAs, por ejemplo, precipitaciones extremas, precipitación, lluvia-escorrentía, afluencia de embalses, caudal, cuantiles de inundaciones, series temporales de inundaciones, y humedad del suelo.
4. Ventajas
Los modelos ML se han utilizado cada vez más para predecir, mapear y monitorizar inundaciones, proporcionando un mejor rendimiento y soluciones más rentables. El avance de los modelos de predicción de inundaciones es esencial para la reducción del riesgo, la sugerencia de medidas políticas, la minimización de la pérdida de vidas humanas, la elaboración rápida de mapas de inundaciones y la reducción de los daños materiales asociados a las inundaciones. La predicción de inundaciones mediante algoritmos de aprendizaje automático es eficaz gracias a su capacidad para utilizar datos de diversas fuentes y clasificarlos y regresionarlos en clases inundables y no inundables.
Los inconvenientes de los modelos basados en la física y la estadística antes mencionados fomentan el uso de modelos avanzados basados en datos, como el ML. Los métodos de predicción basados en datos asimilan los índices climáticos y los parámetros hidrometeorológicos medidos para ofrecer una mejor perspectiva. Muchos algoritmos de ML, por ejemplo, redes neuronales artificiales (ANN), neuro-difusas, máquinas de vectores de soporte (SVM) y regresión de vectores de soporte (SVR), se han reportado como eficaces para las predicciones de inundaciones a corto y largo plazo (Mosavi et al., 2018).
Otra razón de la popularidad de los modelos ML es que pueden formular numéricamente la no linealidad de la crecida, basándose únicamente en datos históricos sin necesidad de conocer los procesos físicos subyacentes. Los modelos de predicción basados en datos y que utilizan ML son herramientas prometedoras, ya que su desarrollo es más rápido y con entradas mínimas.
En la previsión de inundaciones, los métodos tradicionales de predicción de variables de peligro pueden implicar una cadena de modelos hidrológicos e hidráulicos que describen los procesos físicos. Aunque esos modelos permiten comprender el sistema, a menudo exigen un gran esfuerzo de cálculo y muchos datos. Por lo tanto, el uso de modelos de procesos puede no ser siempre factible o necesario en la fase de preparación de un desastre. Los métodos de ML tienen el potencial de mejorar la precisión, así como de reducir el tiempo de cálculo y el coste de desarrollo del modelo. En ese momento, los resultados precisos y oportunos son más importantes que la comprensión del sistema, y el uso de modelos ML de "caja negra" se está generalizando (Wagenaar et al., 2020).

5. Limitaciones
A pesar de las numerosas ventajas de los algoritmos de ML, éstos presentan características importantes que a menudo constituyen limitaciones.
La primera es que son tan buenos como su entrenamiento, mediante el cual el sistema aprende la tarea prevista basándose en datos anteriores. Si los datos son escasos o no cubren variedades de la tarea, su aprendizaje se queda corto y, por tanto, no pueden rendir bien cuando se ponen a trabajar. Por lo tanto, es esencial utilizar un conjunto de datos de entrenamiento sólido.
En segundo lugar, la capacidad de los algoritmos de ML, que puede variar según el tipo de tarea. Esto también puede denominarse "problema de generalización", que indica hasta qué punto el sistema entrenado puede predecir casos para los que no fue entrenado, es decir, si puede predecir más allá del rango del conjunto de datos de entrenamiento. Por ejemplo, algunos algoritmos pueden funcionar bien para predicciones a corto plazo, pero no para predicciones a largo plazo. Estas características de los algoritmos deben aclararse en función del tipo y la cantidad de datos de entrenamiento disponibles, así como del tipo de tarea de predicción.
La tarea de elegir el algoritmo ML más eficaz puede resultar difícil debido a la complejidad de los datos y suele requerir un enfoque de prueba y error de los parámetros de ajuste.
La precisión del algoritmo de ML utilizado depende en gran medida de los parámetros de ajuste y los valores de los mejores parámetros de ajuste no son estáticos para cada conjunto de datos.
6. Referencias
Bonafilia, D., Tellman, B., Anderson, T., & Issenberg, E. (2020). Sen1Floods11: A georeferenced dataset to train and test deep learning flood algorithms for sentinel-1. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, 2020-June, 835–845. https://doi.org/10.1109/CVPRW50498.2020.00113
Casella, G., Fienberg, S., & Olkin, I. (2006). An Introduction to Statistical Learning. In Design (Vol. 102). https://doi.org/10.1016/j.peva.2007.06.006
Huang, C., Chen, Y., Zhang, S., & Wu, J. (2018). Detecting, Extracting, and Monitoring Surface Water From Space Using Optical Sensors: A Review. Reviews of Geophysics, 56(2), 333–360. https://doi.org/10.1029/2018RG000598
IPCC. (2012). Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation. In Special Report of the Intergovernmental Panel on Climate Change (Vol. 9781107025). https://doi.org/10.1017/CBO9781139177245.009
Lamovec, P., Veljanovski, T., Mikoš, M., & Oštir, K. (2013). Detecting flooded areas with machine learning techniques: case study of the Selška Sora river flash flood in September 2007. Journal of Applied Remote Sensing, 7(1), 073564. https://doi.org/10.1117/1.jrs.7.073564
Lee, S., Hahn, C., Rhee, M., Oh, J. E., Song, J., Chen, Y., Lu, G., Perdana, & Fallis, A. . (2012). E-Agriculture in Action: Big Data for Agriculture. In Journal of Chemical Information and Modeling (Vol. 53, Issue 9). http://dx.doi.org/10.1016/j.tws.2012.02.007
Liu, Q., & Wu, Y. (2012). Supervised Learning. Encyclopedia of the Sciences of Learning, January 2012. https://doi.org/10.1007/978-1-4419-1428-6
Mosavi, A., Ozturk, P., & Chau, K. W. (2018). Flood prediction using machine learning models: Literature review. Water (Switzerland), 10(11). https://doi.org/10.3390/w10111536
Peter, L., Matjaž, M., & Krištof, O. (2013). Detection of Flooded Areas using Machine Learning Techniques : Case Study of the Ljubljana Moor Floods in 2010. June 2014.
Rubinato, M., Nichols, A., Peng, Y., Zhang, J. min, Lashford, C., Cai, Y. peng, Lin, P. zhi, & Tait, S. (2019). Urban and river flooding: Comparison of flood risk management approaches in the UK and China and an assessment of future knowledge needs. Water Science and Engineering, 12(4), 274–283. https://doi.org/10.1016/j.wse.2019.12.004
Seo, Y., & Kim, S. (2016). River Stage Forecasting Using Wavelet Packet Decomposition and Data-driven Models. Procedia Engineering, 154, 1225–1230. https://doi.org/10.1016/j.proeng.2016.07.439
Shahabi, H., Shirzadi, A., Ghaderi, K., Omidvar, E., Al-Ansari, N., Clague, J. J., Geertsema, M., Khosravi, K., Amini, A., Bahrami, S., Rahmati, O., Habibi, K., Mohammadi, A., Nguyen, H., Melesse, A. M., Ahmad, B. Bin, & Ahmad, A. (2020). Flood detection and susceptibility mapping using Sentinel-1 remote sensing data and a machine learning approach: Hybrid intelligence of bagging ensemble based on K-Nearest Neighbor classifier. Remote Sensing, 12(2). https://doi.org/10.3390/rs12020266
Veljanovski, T., Lamovec, P., Pehani, P., & Oštir, K. (2011). Comparison of three techniques for detection of flooded areas on ENVISAT and RADARSAT-2 satellite images. Gi4DM 2011 - GeoInformation for Disaster Management.
Wagenaar, D., Curran, A., Balbi, M., Bhardwaj, A., Soden, R., Hartato, E., Mestav Sarica, G., Ruangpan, L., Molinario, G., & Lallemant, D. (2020). Invited perspectives: How machine learning will change flood risk and impact assessment. Natural Hazards and Earth System Sciences, 20(4), 1149–1161. https://doi.org/10.5194/nhess-20-1149-2020
Zehra, N. (2020). Prediction Analysis of Floods Using Machine Learning Algorithms ( NARX & SVM ). International Journal of Sciences: Basic and Applied Research (IJSBAR), 4531, 24–34.