2. Burn Severity
In this step the corrected images are used. In order to generate the burn severity map, the bands B8A and B12 are used. Thus, in the following code (after the function definitions) the bands of both pre- and post-fire images are loaded and the NBR is calculated. As it is already mentioned NBR is calculated using the NIR and SWIR bands of Sentinel-2 in this practice, using the formula shown below:
NBR = (NIR - SWIR) / (NIR + SWIR)
NBR = (B8A - B12) / (B8A + B12)
After calculating NBR for both pre and post-fire images, it is possible to determine their difference and obtain dNBR. Therefore, the difference between the NBR before and after the fire, referred to as dNBR during this practice is calculated. For that, the NBR of the post-images is subtracted from the NBR of the pre-images, as shown in the formula below:
dNBR = pre-fire NBR – post-fire NBR
In addition, the shapefile of the correspondent area (i.e. Empedrado) is used to clip the raster dNBR to obtain an image reflecting only the study area. As during this recommended practice, we are using the area of Empedrado region in Chile, the administrative boundary of the aforementioned area is used. In order to be able to clip the data, the shapefile and dNBR should be in the same projection and thus the shapefile is firt reprojected.
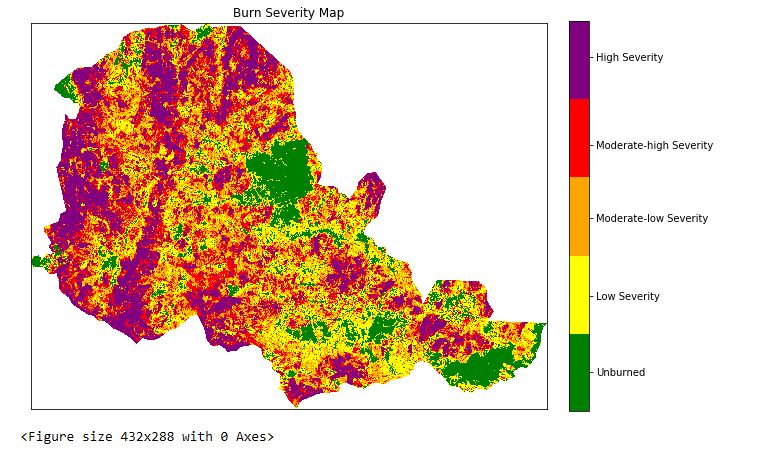
Then, USGS standard is used to classify the burn severity map according to the proposed number ranges, as explained here.
Finally, in order to quantify the area in each burn severity class, the statistics of the raster must be calculated. A transformation of the raster, so that all pixels are assigned one value for each burn severity class is necessary before the calculation.
Run this notebook using Jupyter Notebook
After downloading this notebook, start Jupyter Notebook by searching for it in the Windows start menu or by typing jupyter notebook in the Anaconda Prompt and hitting Enter. After Jupyter Notebook opened in your web browser, search for the script on your computer and open it.
Every cell has to be executed individually. A cell, which is still processing is marked by an * and a finished cell with a number. Cells are executed by clicking on the cell and hitting Shift + Enter. Alternatively, run the entire notebook sequentially (i.e. one cell at a time) click on Cell > Run All (make sure all the configuration options are set correctly).
Optional: You can run the python script (.py) either in Spyder (an IDE that comes bundled with Anaconda) or in a terminal. This may yield better performance.
The results after executing the code should look like the following figures: