A continuación se describen los procedimientos paso a paso realizados para la generación de mapas a escala 1:25.000, de la expansión y contracción de cuerpos de agua partir de imágenes satelitales RapidEye y Spot 5, mediante una serie de explicaciones tutoriales centradas a explicar el flujo de trabajo utilizando un paquete de software PCI Geomatica 2013 (disponible en: http://www.pcigeomatics.com/).
Este procedimiento paso a paso se describe en las siguientes secciones:
Fase 1: Acceso y preprocesiamento de datos
Paso 1.1: Pre-procesamiento - Descarga de imágenes
Paso 1.2: Pre-procesamiento- Análisis de períodos
Paso 2: Pre-procesamiento - Correcciones geométricas
Paso 3.1: Correcciones atmosféricas/radiométricas
Paso 3.2: Generación del modelo de corrección
Paso 4: Procesamiento - Máscaras de Nubes
Paso 4.1: Procesamiento -Crear umbral para la discriminición de nubes
Paso 4.2: Procesamiento - Creación de polígonos
Paso 4.4: Eliminación de áreas mínimas
Fase 2: Procesamiento de datos
Paso 5: Procesamiento - Obtención de índices espectrales
Paso 6: Relación Discriminante de Fisher (FDR)
Paso 7.1: Primera parte del modelo – Área efectiva de estudio
Paso 7.2: Segunda parte del modelo – Áreas efectivas de agua
Paso 7.3: Tercer parte del modelo – Expansión
Paso 7.4: Cuarta parte del modelo –Desecación
Paso 7.5: Quinta parte del modelo – Contracción
Paso 7.6: Sexta parte del modelo – Cálculo de áreas para análisis
Fase 3: Postprocecamiento
Paso 8: Creación de mapas y salidas gráficas y correlación de resultados
Ejemplo del producto resultante
Fase 1: Acceso y preprocesamiento de datos
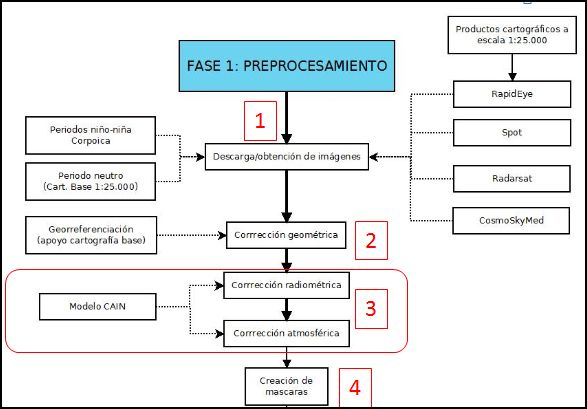
Paso 1.1: Pre-procesamiento - Descarga de imágenes
La consulta y descarga de imágenes se puede realizar a través de las diferentes bases de datos disponibles en Internet como son:
- Datos de PDSI (Palmer Drought Severity Index) suministrados por CORPOICA (Corporación Colombiana de Investigaciones Agropecuarias). Vamos a utilzar datos de PDSI en Paso 1.2.
- Series históricas de fenómenos Niño y Niña, suministrados por Corpoica, con base en la información oficial reportada por el Instituto de Hidrología, Meteorología y Estudios Ambientales (IDEAM). Vamos a utilzar estos datos en Paso 1.2.
- Banco Nacional de Imágenes para Colombia (BNI) del Instituto Geográfico Agustín Codazzi (IGAC) para metadatos de imagenes ortorectificadas de RapidEye, Spot, Radarsat, CosmoSkyMed y otros. El BNI es un Geoservicio de tipo Catalog web Service- CSW dirigido a la gestión de entidades gubernamentales, el cual suministra un catálogo definido a través de una interfaz común para la recuperación, captura y consulta de metadatos (NTC-4611 Segunda Actualización), que almacena imágenes referentes a datos de tipo raster del territorio colombiano en niveles de procesamiento 1A y 1B. La URL de acceso al servicio CSW es: (http://bni.igac.gov.co:81/home/srv/es/main.busqueda).
Para el procesamiento digital de imágenes usaremos los datos suministrados por el BNI sobre la zona de estudio, ingresando a la siguiente página: http://www.bni.gov.co/portal/public/classic/Busqueda?faces-redirect=true

La figura anterior muestra la visualización de una imagen RapidEye del año 2011.


Figura: Imagen RapidEye. Año 2011. Fuente BNI.
Fase 1: Acceso y preprocesamiento de datos (continuación)
Este paso incluye el análisis de fechas de los eventos climatológicos Niño y Niña, la consulta y descarga de imágenes disponibles, y sus posteriores correcciones geométricas, radiométricas y atmosféricas.
Paso 1.2: Análisis de periodos
La selección de imágenes se realizó teniendo en cuenta dos factores:
- series históricas de fenómenos Niño y Niña, suministrados por Corpoica, con base en la información oficial reportada por el Instituto de Hidrología, Meteorología y Estudios Ambientales (IDEAM), y
- los valores de PDSI (Palmer Drought Severity Index) calculados por Corpoica. Este índice clasifica los períodos de tiempo en seco y húmedo a partir del balance entre el suministro y la demanda de humedad (cf. figura abajo). De esta manera se pueden consultar las imágenes empleadas para el análisis multitemporal de la contracción y expansión de los cuerpos de agua y el análisis de sequías.
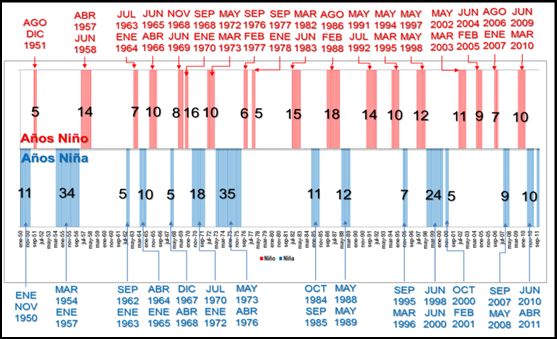
Figura : Períodos de análisis de los eventos Niño y Niña. Fuente Corpoica 2013.
Paso 2: Pre-procesamiento - Correcciones geométricas
La georeferenciación es el proceso de asignación de coordenadas a los píxeles en un sistema de referencia establecido. Una transformación geométrica cambia la posición de los píxeles de una imagen sin modificar los valores de los mismos. Este es un proceso importante para los análisis multitemporales puesto que asegura que los valores de reflectancia capturada por el sensor satelital en diferentes fechas, correspondan al mismo punto en la superficie (IGAC, 2004).
Este proceso utiliza diferentes algoritmos de asignación de coordenadas como: vecino más cercano, transformación bilineal y convolución cúbica. En este trabajo se decidió utilizar el primer algoritmo puesto que éste no altera los valores originales del píxel, considerando las siguientes características:
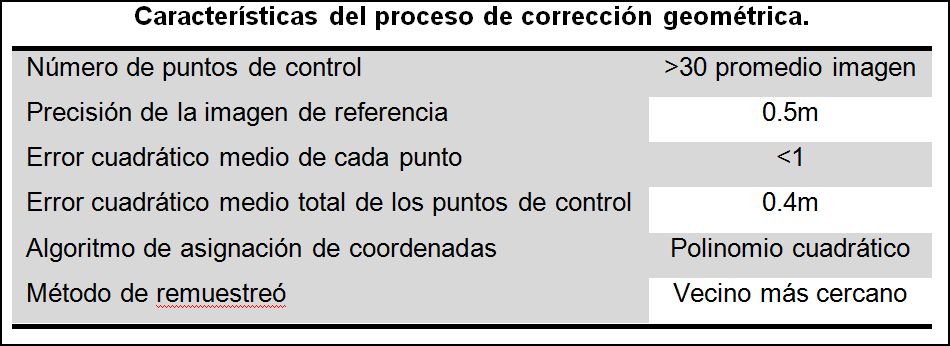
La corrección geométrica puede abordarse a través del módulo auxiliar  Orthoengine, el cual resulta bastante interactivo, y permite corregir imágenes de satélite o fotografías aéreas, incluso con modelos orbitales, así como calcular modelos digitales del terreno a partir de pares estereoscópicos.
Orthoengine, el cual resulta bastante interactivo, y permite corregir imágenes de satélite o fotografías aéreas, incluso con modelos orbitales, así como calcular modelos digitales del terreno a partir de pares estereoscópicos.

En este caso, utilizaremos la imagen Rapideye ya georeferenciada como base para corregir una imagen SPOT 5 del 2010.
- El primer paso consiste en salvar el nombre del proyecto en un archivo .prj, definiendo el método de modelamiento a seguir (File - New):
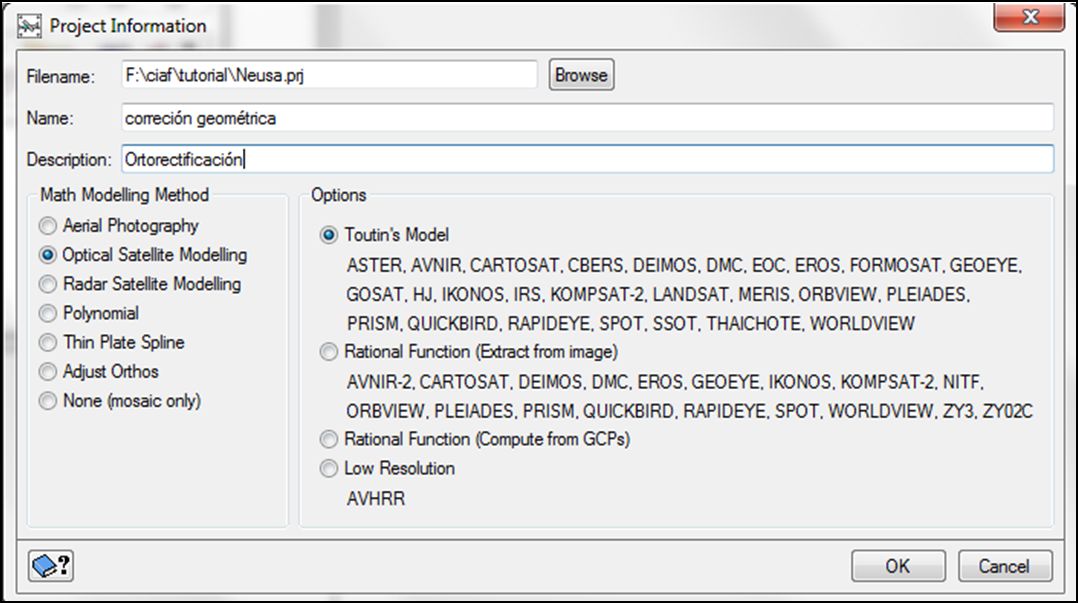
El programa se inicia con una ventana que requiere introducir los datos de un proyecto (File –New). En primer lugar se introduce un nombre de referencia para ese proyecto (p.ej. Rapideye_referencia), que puede extenderse con una descripción más cualitativa. Luego se indica qué tipo de corrección se va a abordar, si se trata de fotografía aérea, modelo orbital, polinómico, funciones spline, racionales o simplemente realizar mosaicos. Algunas de estas opciones requieren parámetros adicionales, como el tipo de cámara o de sensor y un MDT para la orthorectificación. En nuestro caso, indicaremos que se trata de un modelo orbital, para corregir imagen a imagen. El paso siguiente es indicar el método de corrección Toutin´s Model el cual emplearía los datos orbitales de nuestra imagen más los puntos de control GCPs extraídos de la imagen de referencia.
- Posteriormente indicamos los datos de la proyección de referencia:
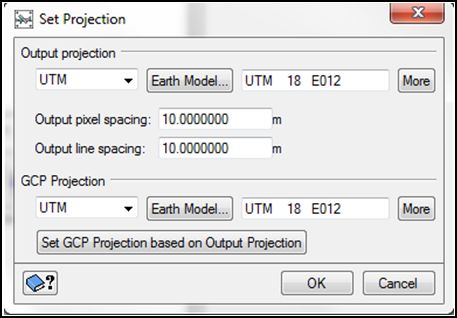
Indicaremos: UTM, Elipsoide E012 (WGS 84), Zona 18, UTM Row S (hemisferio Norte). El tamaño del píxel de salida lo fijaremos a 10x10 metros. La proyección de los puntos de control, será la misma que la de referencia (Set GCP Projection base on Output projection).
- A continuación, dentro de Processing step señalar la opción para seleccionar los datos de entrada (Data Input):
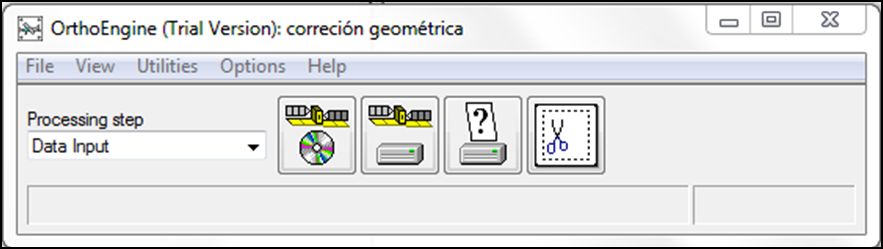
En este caso leeremos los datos a través de la opción Read CD-ROM data. Seleccionaremos el formato de nuestra imagen SPOT 1-5 (DIMAP) seleccionamos el archivo de nuestra imagen original de toda la escena: (imagery), marcamos todos los canales. Esto nos creará una nueva imagen con metadatos en donde estarán todos los datos orbitales y puntos de control del satélite en un solo archivo. La guardamos en la misma carpeta de la imagen con un nombre apropiado: (ej: Imagen Spot_2010), incluyendo una descripción apropiada:
- A continuación abrimos en Focus los archivos creados: (Imagen Spot_2010_data) y el reporte con los metadatos incluidos:
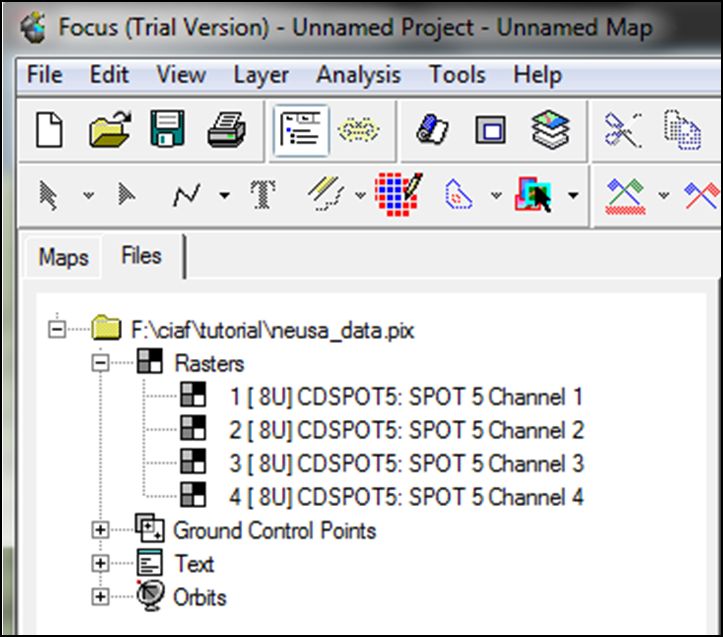
- Posteriormente seguimos con el siguiente paso, seleccionando en processing step los puntos de control (GCP Collection):
Puede utilizarse como origen de esos puntos, un archivo con coordenadas GPS, introducirlos por teclado o por tableta, extraerlos a partir de una imagen ya georeferenciada o de vectores de referencia.
En esta práctica utilizaremos la imagen Rapideye (rapideye_2009.2) como referencia. Para comenzar el proceso, seleccionamos la imagen no corregida (Rapideye_referencia _data) con la opción Open Image (primer botón del panel, desde la izquierda).  Al abrirla, puede seleccionarse la combinación de bandas que nos resulte de mayor interés, con el tipo de realce que convenga.
Al abrirla, puede seleccionarse la combinación de bandas que nos resulte de mayor interés, con el tipo de realce que convenga.
Una vez abierta, se pulsa el botón Collect GCPs Manually,  lo que abre otro panel. En ese panel hay que indicar cuál es el origen de las coordenadas de referencia (Ground Control Source). Seleccionar la opción Geocoded image, y pulsar sobre la imagen Rapideye (rapideye_2009.2). Se recomienda utilizar la misma combinación de bandas que hayamos empleado con la imagen sin corregir.
lo que abre otro panel. En ese panel hay que indicar cuál es el origen de las coordenadas de referencia (Ground Control Source). Seleccionar la opción Geocoded image, y pulsar sobre la imagen Rapideye (rapideye_2009.2). Se recomienda utilizar la misma combinación de bandas que hayamos empleado con la imagen sin corregir.
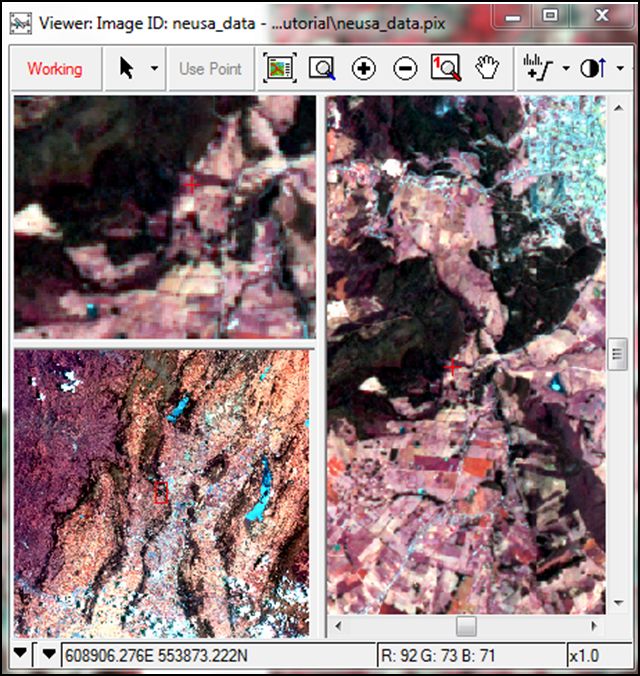
Introducimos el modelo digital del terreno DEM, incluido en el archivo (DEM_30_Geosp). Si todo el proceso ha sido correcto, aparecerán las siguientes ventanas (Fig. 3):

Fig. 3. Ventanas de trabajo en Orthoengine, para la colección de GCP´s.
A la izquierda está la original sin corregir, a la derecha, la de referencia, y en el centro la ventana donde aparecen las coordenadas de los puntos de control que vayamos introduciendo. Se seleccionan de la forma siguiente. Observar puntos en la imagen de referencia que se ven con claridad en la no corregida. Seleccionar uno, con el nivel de zoom y de realce que se necesite, Cuando estemos satisfechos, pulsar Use Point consecutivamente en las dos imágenes. Aparecerán las coordenadas seleccionadas en la ventana central. Luego pulsar Accept en esa ventana para que el punto pase a considerarse válido. Cada punto puede tener una etiqueta propia si se requiere. A partir del 4º punto, el programa ya puede calcular la función de ajuste (en caso de ser de primer grado, si es de segundo, necesita 6 puntos) y facilita el error promedio global y el promedio en X e Y, así como el error de cada punto. Cuando está activada la opción Auto Locate, a partir del 4º punto al seleccionar un punto en la ventana de referencia, aparecerá su posición aproximada en la ventana de la imagen a corregir, o bien seleccionando Extract Elevation para cada punto que hayamos seleccionado. Esto ayudará a localizar algunos rasgos del mapa en la imagen. Ojo, no aceptar necesariamente ese punto, pues el que estima el programa con el modelo que va construyendo según se le introducen puntos, pero eso no es correcto hasta que están todos los puntos seleccionados, así que habrá que mover el punto sugerido hasta el lugar más preciso que se pueda localizar. El proceso se continuará hasta tener 15-20 puntos y un error promedio inferior a 1 píxel. Si observamos puntos que dan mucho error, pueden corregirse haciendo doble clic sobre ellos, revisando si están las coordenadas bien posicionadas y, si no es el caso, moverlas y volver a pulsar Use Point en cada una de las dos ventanas. También pueden eliminarse si se descubre que la localización no es muy fiable. Hay que señalar también 3 puntos de verificación, de cara a estimar de modo más riguroso el error de la corrección. Basta cambiar el carácter del punto en la opción desplegable GCP, cambiándola a Check Point. Podemos ver el error residual de nuestra corrección, señalando la opción de Residual Report en GCP TP Collection.
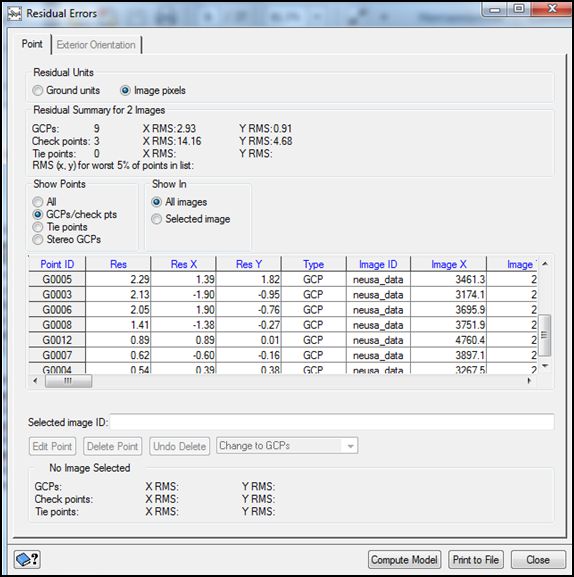
Al terminar el proceso, cerrar la ventana. En el menú principal de Orthoengine, convendrá salvar los puntos para un futuro uso, imprimirlos o modificarlos. Esto se obtiene con el menú Options Export GCP. Pueden exportarse a un segmento del archivo de imagen, de otra imagen o a un fichero ASCII. Salvarlo a un archivo de texto y como un segmento de la imagen a corregir, para el caso de que se quieran luego modificar los puntos o añadir otros. En caso de que queramos recuperar puntos de un archivo de texto, puede utilizarse la opción del menú GCP denominada Import GCP from File. Esta opción permite leer coordenadas de puntos de control en distintos formatos. Hay que indicarle al programa en qué orden están separadas las variables de cada punto: típicamente será identificador del punto, coordenada Píxel, Línea, X, Y (esto equivale al formato IPLXY del módulo Import GCP).
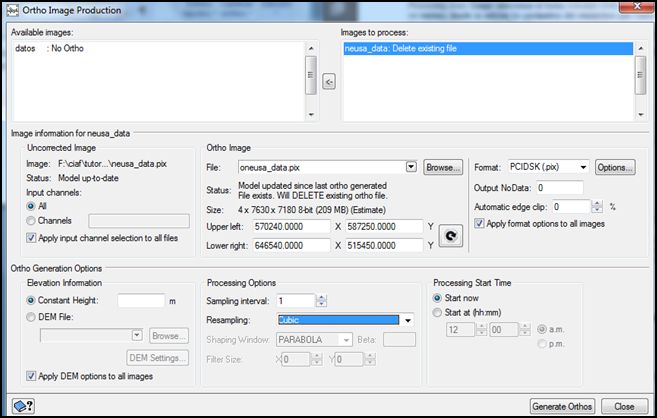
Una vez que el error sea adecuado, imprimir las ecuaciones de ajuste y los puntos finalmente seleccionados, tanto de control como de verificación. Ésto se obtiene en la pestaña Project Report, del menú Reports - Processing Steps. Ahí se indica la posibilidad de salvar a un archivo ASCII las ecuaciones (Geometric Model), los puntos (Point Information) y el área georeferenciada. Finalmente, ya estamos en condiciones de pasar a la última fase, el remuestreo de la imagen original a la nueva posición. Para ello seleccionamos Geometric Correction desde la ventana Processing Steps. Luego seleccionar el botón Schedule Ortho Generation, que abre una nueva ventana, donde se señalan los parámetros del remuestreo que vamos a realizar a partir de las ecuaciones previamente obtenidas:
En esta nueva ventana, se seleccionan las imágenes a corregir, que pasan pulsando la flecha de la lista Available Images a Images to Process. Seguidamente, se introducen los canales que quieren corregirse (las bandas que tendrá la nueva imagen, en principio todas las originales), el nombre de la imagen de salida (indicar un nombre descriptivo adecuado), y las coordenadas de la zona que se va a corregir. Introducir las que coincidan con la ventana de la imagen de referencia. El tamaño del píxel ya se indicó al iniciar el proceso, así como los parámetros de la proyección de salida. Finalmente se señala el método de interpolación (Nearest, Bilineal o Cubic, señalar el cúbico), y se pulsa el botón Correct Images. Este último proceso puede programarse para otra hora, si el volumen de las imágenes a corregir es muy grande, lo cual no es nuestro caso.
Ahora puede comprobarse la calidad de la corrección, abriendo la nueva imagen en Focus y superponiéndola sobre la original.

Paso 3.1: Correcciones atmosféricas/radiométricas
La radiación electromagnética que llega al sensor es almacenada como niveles digitales ND relacionados con las propiedades radiométricas de las coberturas, sin embargo estas no representan magnitudes físicas. Por ello es necesario convertir los ND a valores de radiancia Lλ, y así posteriormente obtener la reflectancia de superficie.
Sin embargo Lλ no depende únicamente de las propiedades de la cubierta, por lo que se requiere convertir de nuevo a una magnitud física como es la reflectancia (ᴩλ) de la cubierta en la banda λ captada por el sensor.
El uso de ᴩλ reduce las variaciones de la radiancia, permitiendo la comparación entre escenas de diferentes satélites adquiridas en fechas distintas. Para este trabajo emplearemos el modelo basado en el método simple de Chavez (1996) y en la ecuación propuesta por Pons & Sole (1994) para convertir los niveles digitales ND a niveles de radiancia y así obtener los niveles de reflectancia:
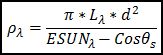 (Chandler et al., 2009, p. 900)
(Chandler et al., 2009, p. 900)
Donde:
- ᴩλ = Reflectancia planetaria TOA o reflectancia en el techo de la atmósfera (Top of Atmosphere Reflectance) [sin unidades]
- θs= angulo zenital de sol. Los valores de θs se encuentran en los metadatos (archivos .MTL o .WO) de cada imagen tomada por cada sensor.
- π = constante matemática ~3.14150 [sin unidades]
- Lλ = radiancia espectral a la abertura del sensor [W/(m2 sr μm)]
- d=distancia de la tierra al sensor [unidades astronómicos]. EL valor de d, depende del día y año cuando se realizó la captura de la imagen.
- ESUNλ = medio irradiación solar exoatmosférica (mean exoatmospheric solar irradiance) [W/(m2 μm)]. ESUNλ se puede encontrar en resúmenes de trabajos previos (Chandler et al., 2009).
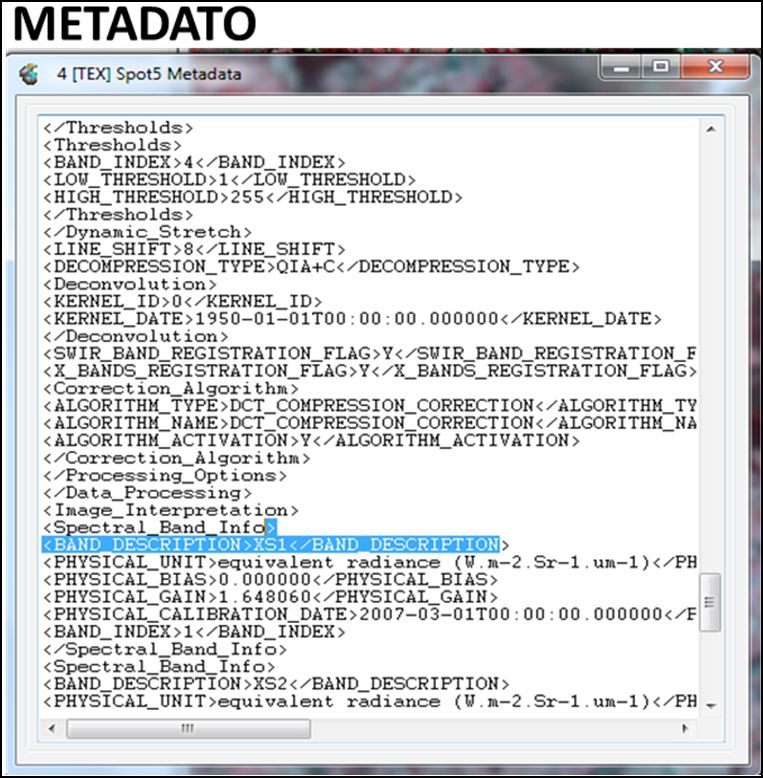
Arriba: Angulo zenital del sol en los metadatos de RapidEye.
Este procedimiento llamado también corrección atmosférica se desarrolló bajo el software Geomatica PCI 2013, debido a su sencillez para modelar y su capacidad de gestión.
Paso 3.2: Generación del modelo de corrección
Las imágenes Spot 5 fueron sometidas a la evaluación de varios índices, realizando posteriormente un análisis de sensibilidad, descartando así qué índice se ajusta mejor para la extracción de superficies de agua. Para estos procesos se generó un modelo que fue llamado CAIN (Correcciones Atmosféricas e Índices). Para este proceso utilizaremos el módulo llamado: Modeler, el cual se utiliza para generar funciones adaptadas a las necesidades del usuario, mediante un lenguaje de programación en macros; llamados Pipelines o tuberías. PCI modeler está diseñado para ser una poderosa herramienta de análisis y además es fácil de usar, ya que posee una gran variedad de algoritmos que se puede interconectar mediante tubos o pipeline (Street, Hill, & Lb, 2003).

Dicho módulo se encuentra desplegado el panel superior de iconos Geomática 2013, tal y como se aprecia en la siguiente figura:

Figura: Menú de inicio de PCI y ubicación del módulo de programación Modeler en rojo.
Para poner en marcha este modelo, primero hay que describirlo y comprenderlo:
- Iniciaremos creando un nuevo modelo y salvándolo con un nombre apropiado desde el comando file:

- Posteriormente cargaremos cada una de las librerías de algoritmos necesarios para la implementación del modelo CAIN. Dichas librerías se encuentran alojadas en el menú Module Librarian, ubicado en la parte superior del menú principal:

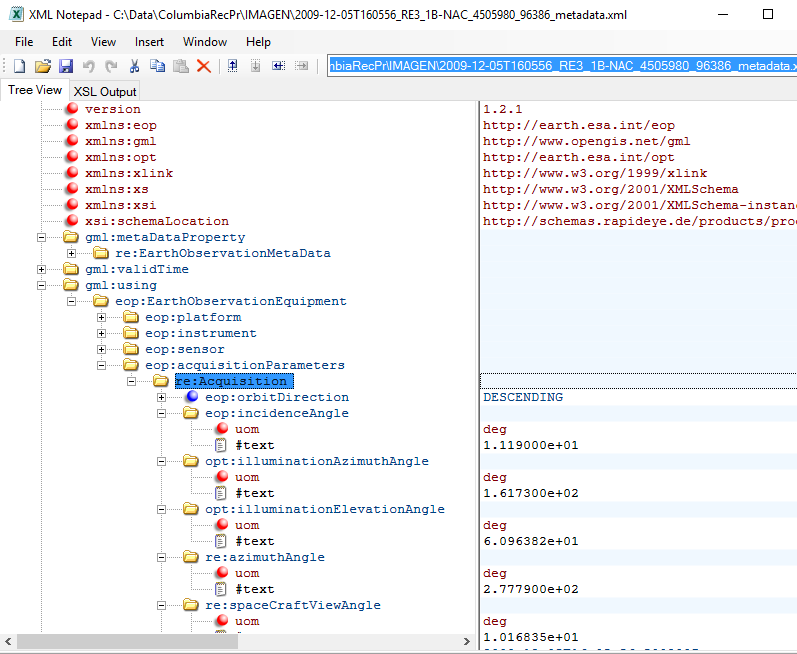
Las principales librerías a utilizar son las siguientes: COMMENT, IMPORT, ARICONST, CRHN32R, MODEL, VIEWER Y EXPORT:
- Posteriormente procederemos a construir el modelo de corrección atmosférica comentado en la ecuación inicial, conectando mediante tuberías cada uno de los algoritmos importados desde Modeler (Dichas tuberías definen cada uno de los canales Raster o bandas a utilizar).
- Ahora empezaremos a construir el modelo paso a paso, en la ventana de Modeler cargando una a una las librerías a utilizar:
- Click derecho >> Common Modules
- Common Modules >> Import
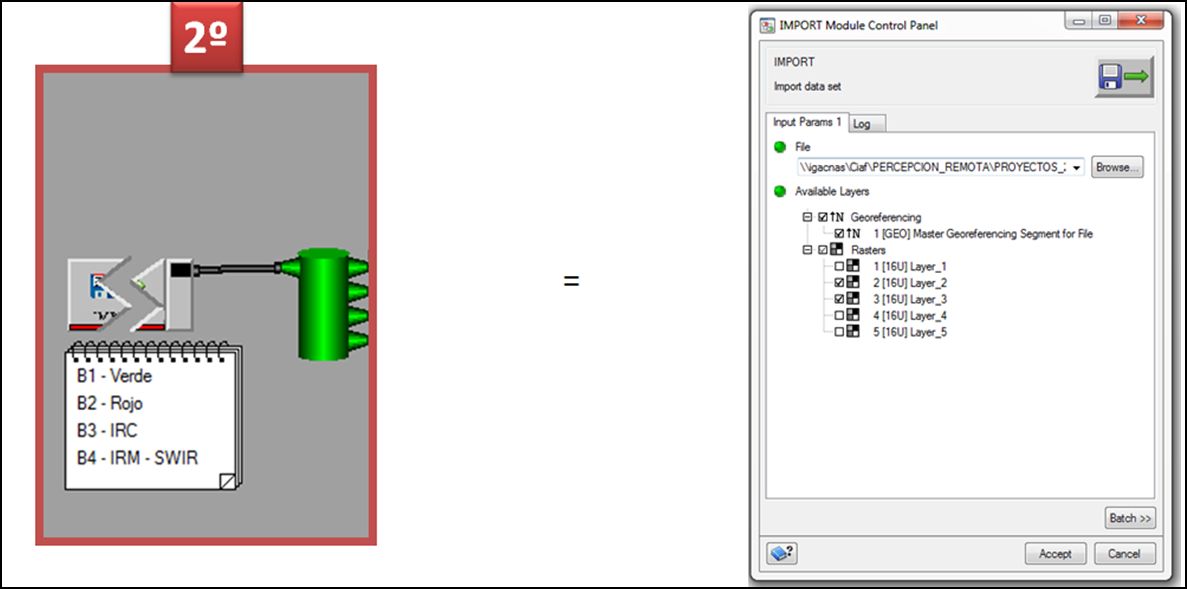
Este módulo importa el conjunto de datos e imágenes necesarios que serán procesados posteriormente,tal y como se muestra en el siguiente diagrama (figura abajo), en donde aparece toda la estructura del modelo CAIN a través de la red de algoritmos conectados:
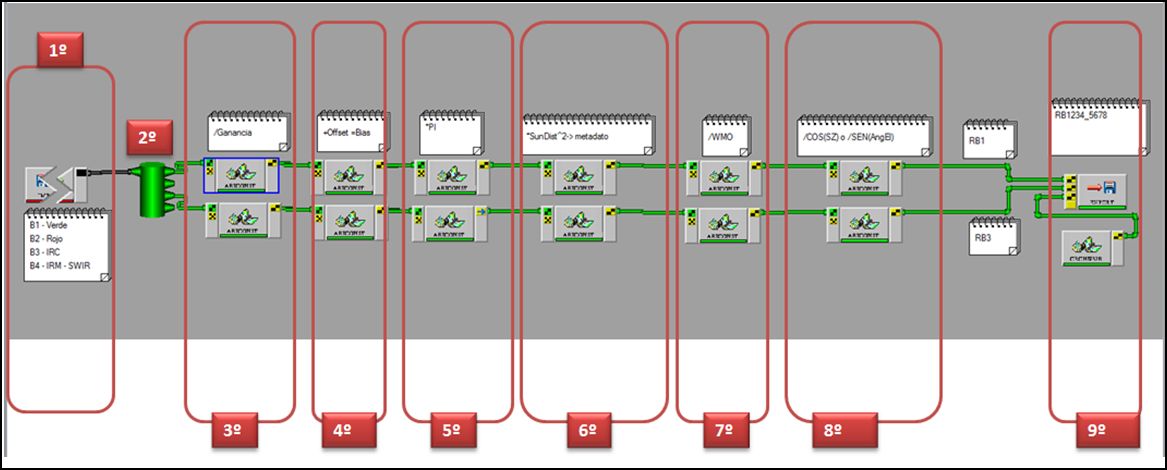
A continuación describiremos cada uno de los pasos que componen la estructura del modelo CAIN:
- En este primer paso, se cargará el archivo que contiene todas las bandas de la imagen SPOT.

Posteriormente separamos cada una de las bandas de la imagen:
- Click derecho >> Common Modules
- Common Modules >> Split
El módulo SPLIT divide los canales o bandas en vías de procesamiento separado.
El siguiente paso consiste en buscar la ruta de la imagen y daremos aceptar. Realmente para estas correcciones trabajaremos solo con las Bandas 2 (rojo) y 3 (infrarojo) de Spot 5 (para RapidEye son bandas 3 y 5), ya que son las necesarias para crear el índice espectral.
A continuación se une mediante una tubería el módulo IMPORT y el modulo SPLIT. Al unirse el SPLIT toma tonalidad verde. (Ésto quiere decir que el canal ya ha sido asignado correctamente).
Seguidamente agregamos el siguiente algoritmo de procesamiento:
- Menú>> View >> Module Librarian
- Find >>Escribir ARICONST>> Arrastra al espacio de trabajo

Definimos el valor de la constante y el operador a procesar con la capa raster:
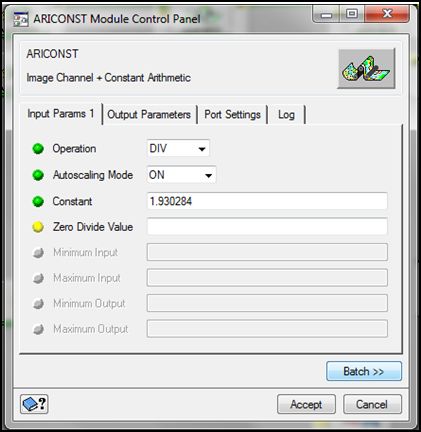
- Find >>Escribir ARICONST>> Arrastra al espacio de trabajo:
Posteriormente implementar del mismo módulo ARICONST 5 veces.
En el primer ARICONST, comenzaremos a buscar los parámetros incluidos en los metadatos de la imagen.
Este caso pondremos el valor de ganancia para la banda a procesar, el cual aparece en los metadatos como GAIN, o valor de ganancia, este número hace referencia al coeficiente multiplicativo.
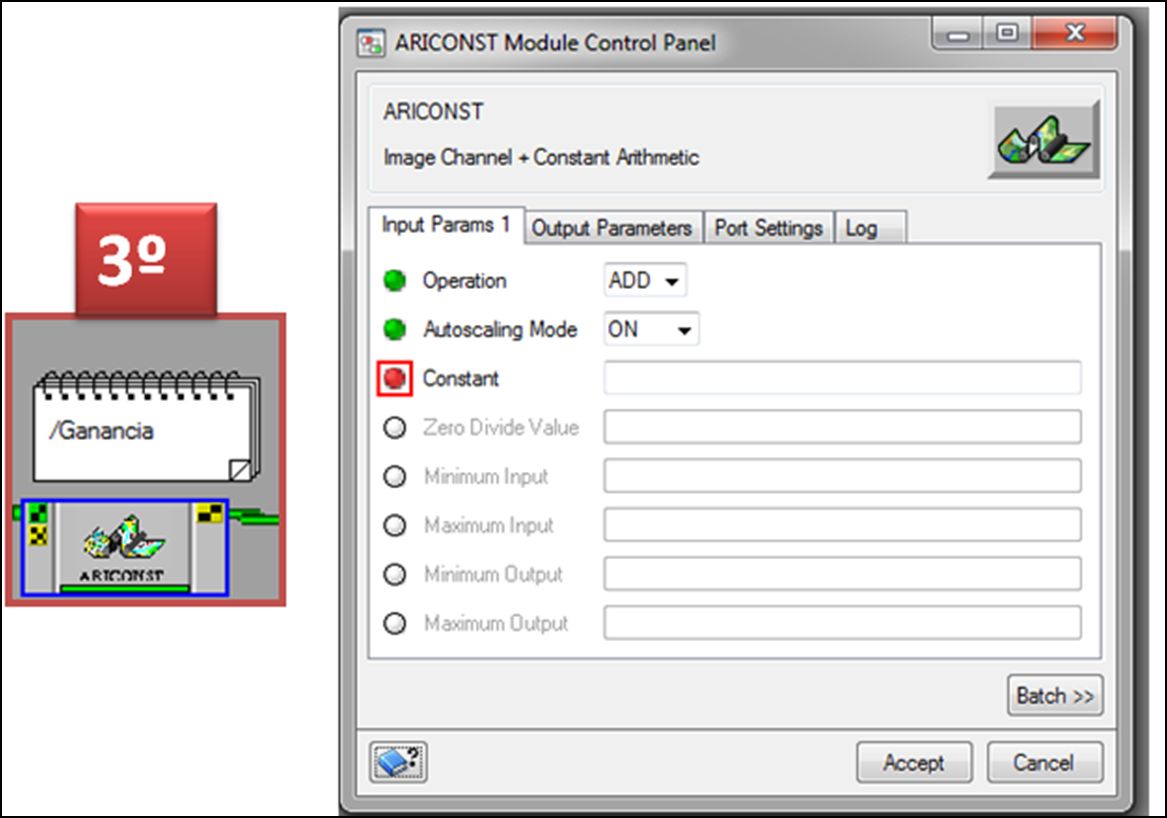
En el segundo módulo ARICONST incluiremos el valor del Coeficiente Aditivo, también llamado BIAS, al igual que GAIN se obtiene en el metadato.
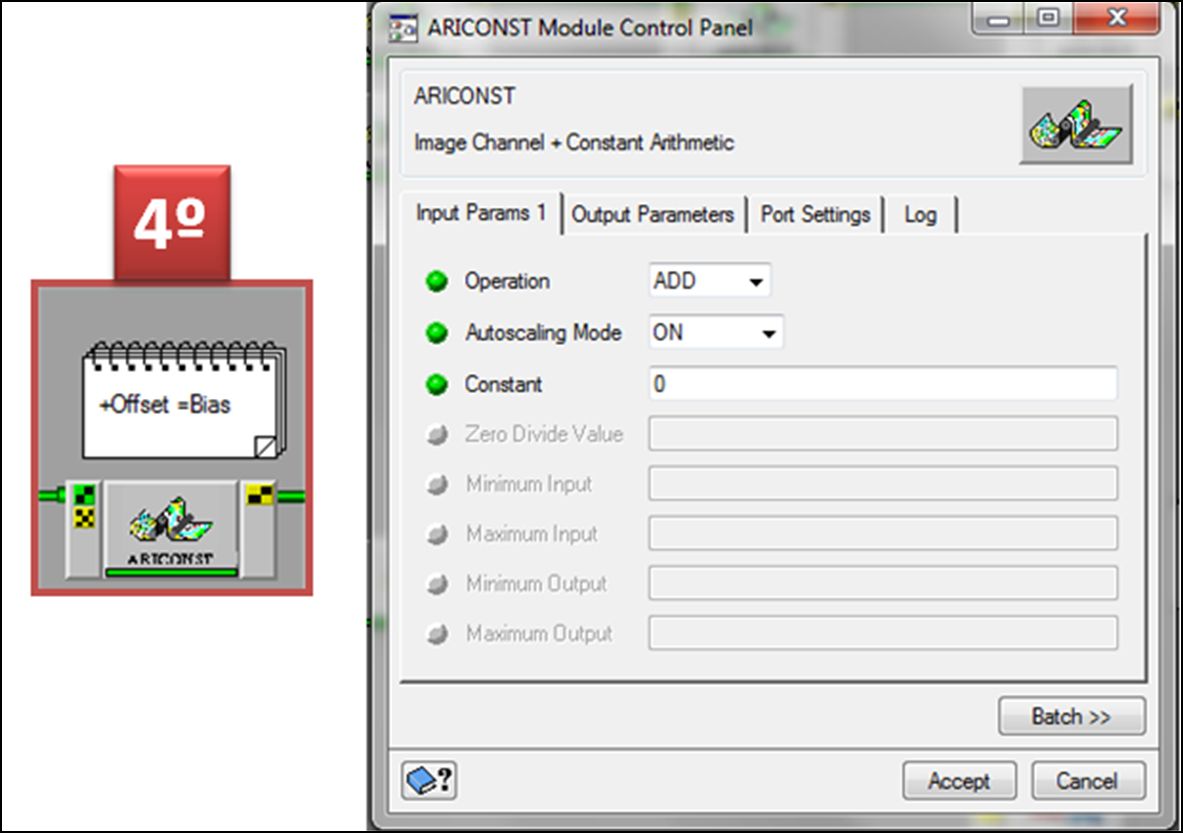
En el tercer módulo incluiremos el valor de (π), el cual quedará siempre constante:
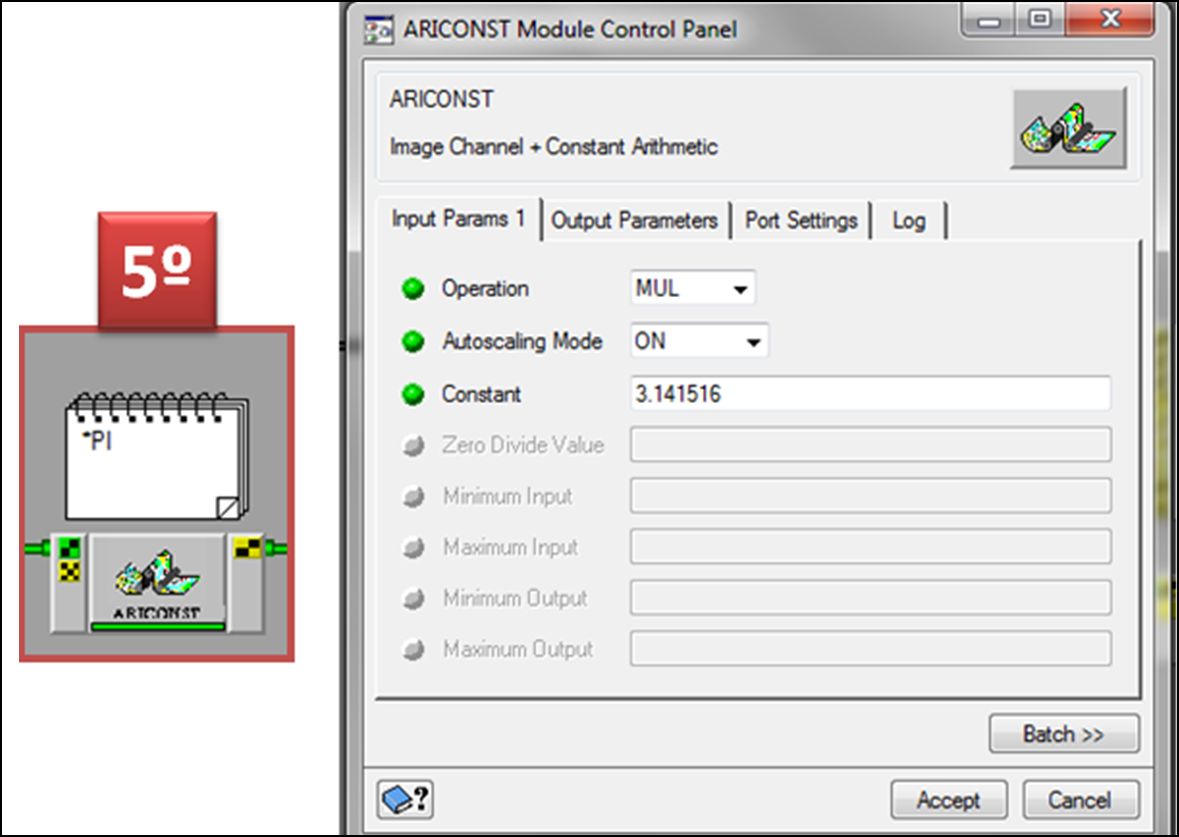
Parta el siguiente módulo, observaremos también dentro de los metadatos el valor de SUNDIST como el factor que considera la distancia del Sol. Este valor será elevado al cuadrado antes de incorporarlo al modelo y se refiere a la distancia entre el Sol y la Tierra para el día de la toma.
Para el caso de nuestra imagen SPOT será 1.031…
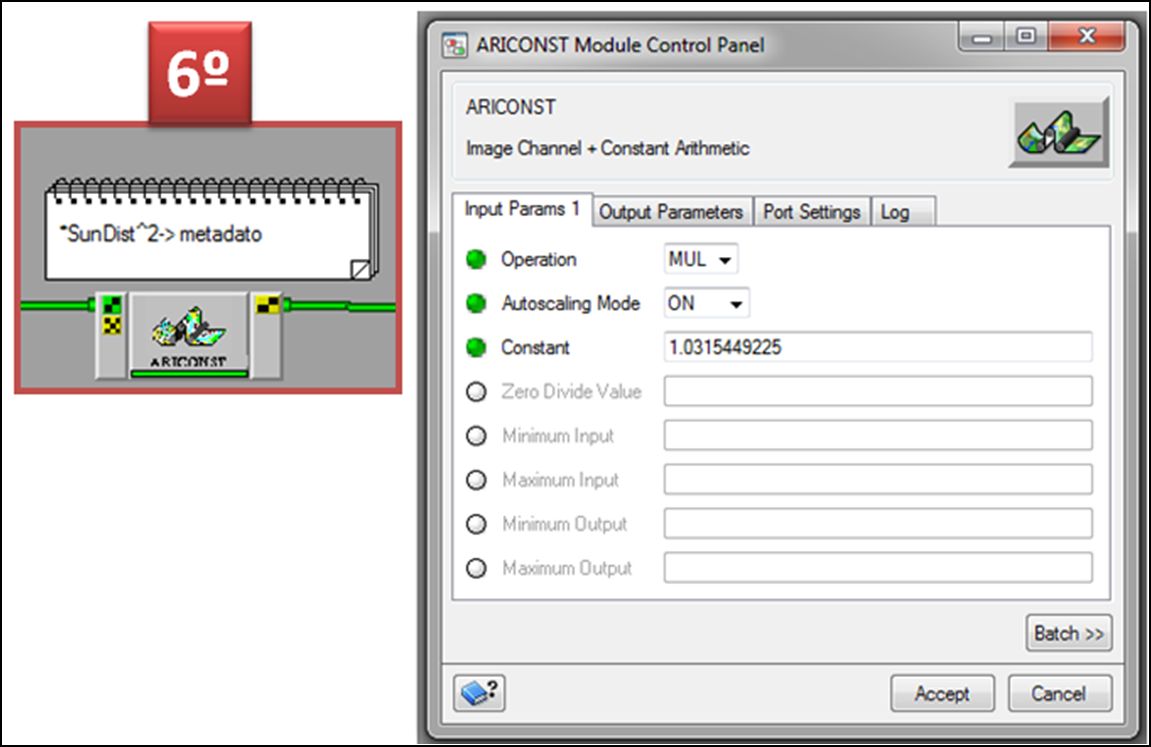
Posteriormente en el módulo marcado como WMO, incluiremos el valor que hace referencia a la energía exoatmosférica para cada una de las bandas del sensor: Y, que en nuestro caso para la banda 2 será de 1859.8
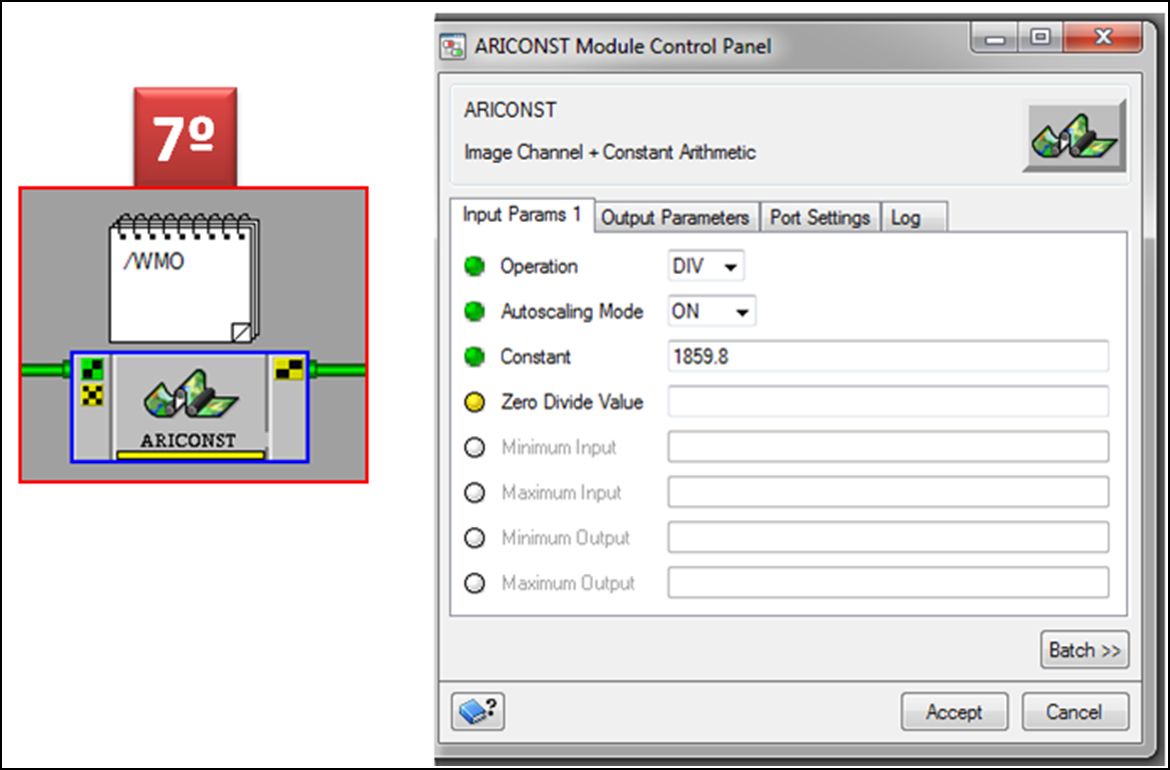
Posteriormente en el módulo marcado como COS (SZ)= SEN(AngElev), adicionaremos el valor que hace referencia al seno del ángulo de elevación, esta información se encuentra en el metadato
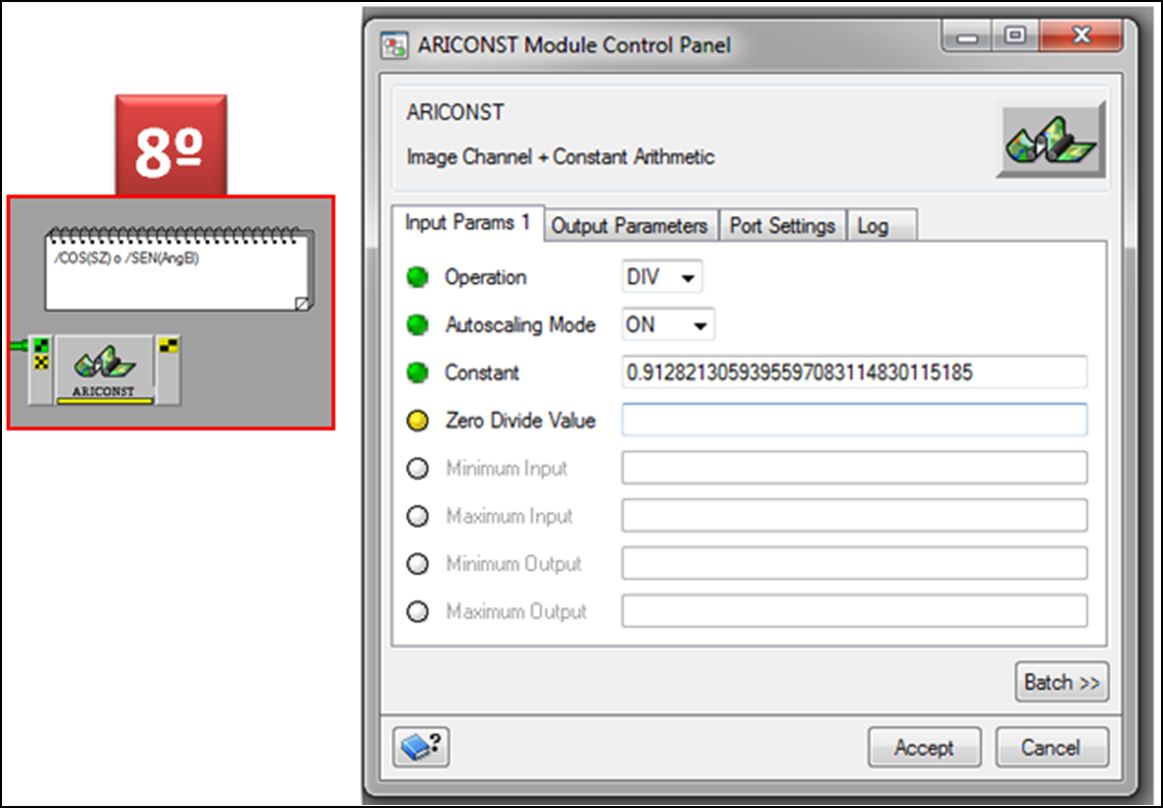
Hasta aquí nuestro espacio de trabajo de PCI Modeler. Tendría que aparecer de la siguiente manera:
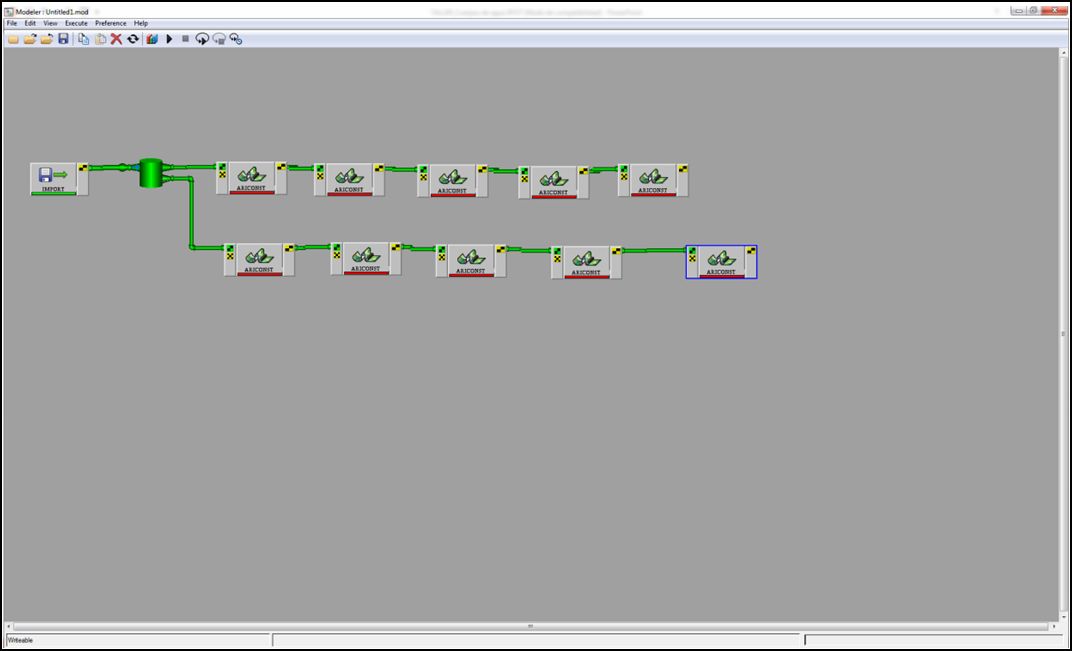
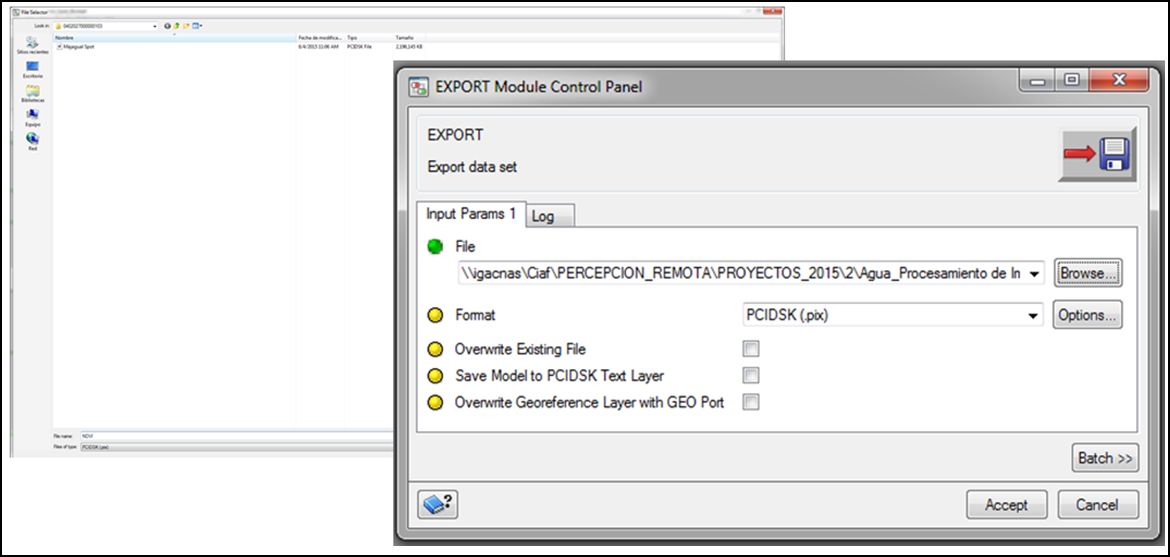
A continuación incluiremos el módulo que permite salvar y exportar los archivos resultantes:
- Click derecho >> Commom Modules >> Export
Este módulo almacena el conjunto de datos después del procesamiento.
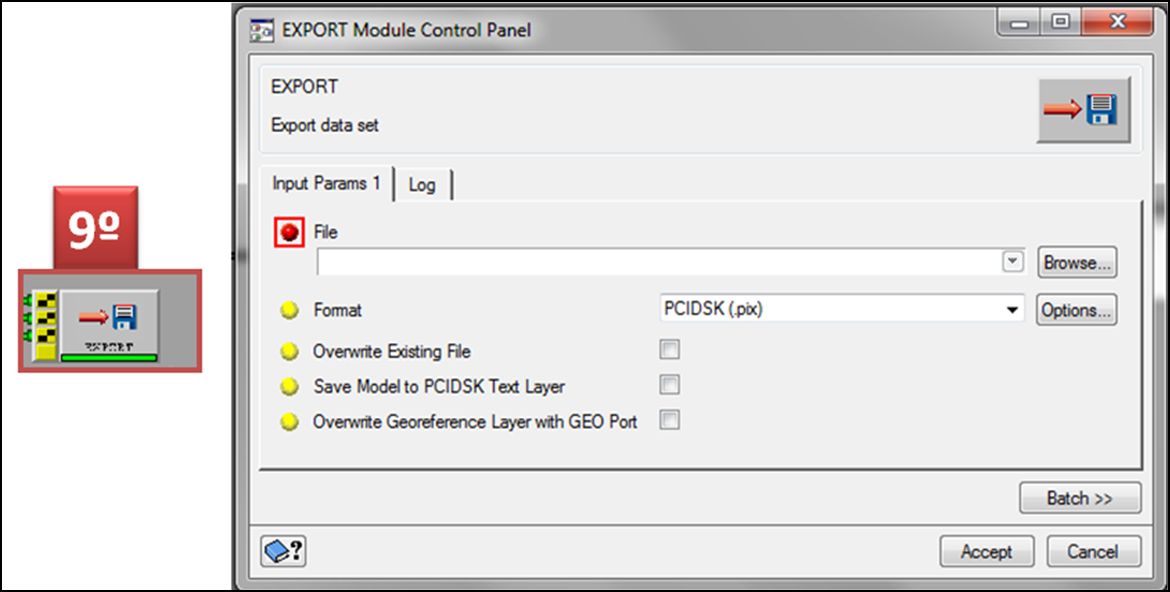
Daremos una ruta y nombre apropiado al nuevo archivo generado:
Posteriormente corremos el modelo generado:

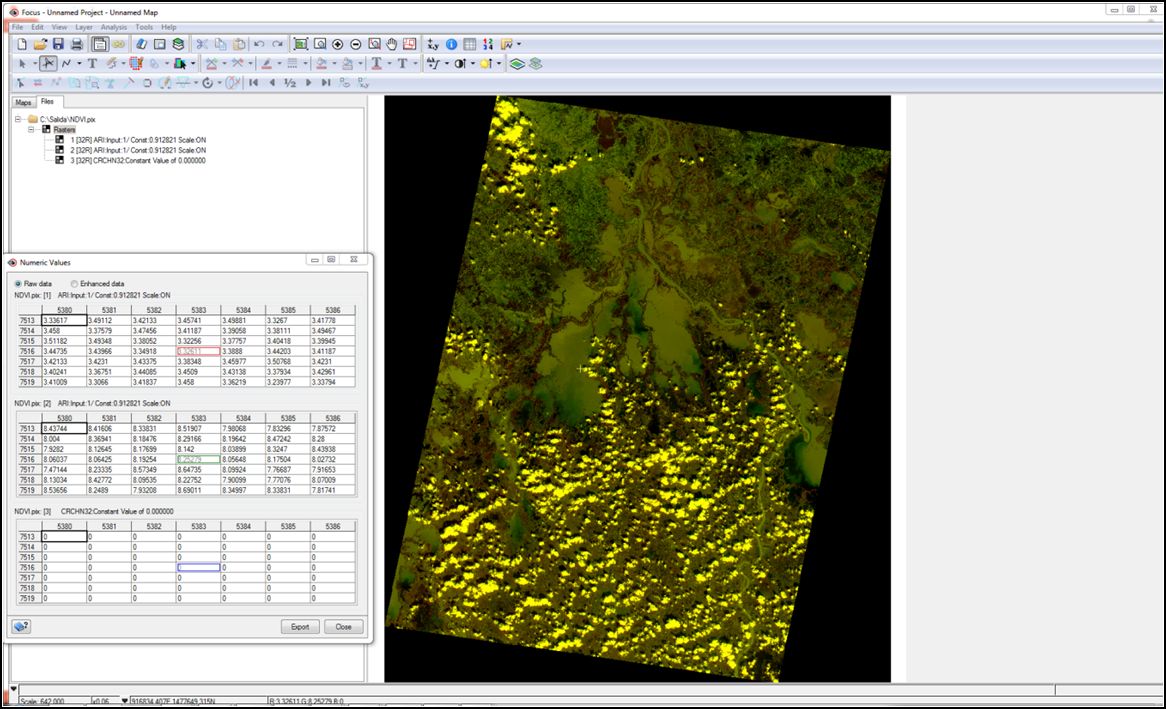
De esta manera completaríamos todo el modelo de procesamiento CAIN para la correción atmosférica y obtención de imágenes en valores de reflectancia:
Paso 4: Procesamiento -Máscaras de Nubes
Con el fin de identificar y eliminar aquellas áreas con presencia de nubes dentro de las imágenes, procederemos a la creación de una máscara que nos permita excluir la información no deseada.
Este procedimiento lo desarrollaremos desde PCI Geomatica 2013. Como cualquier programa profesional de teledetección, FOCUS permite generar al usuario sus propias rutinas de procesamiento. Para ello dispone de dos opciones. Por un lado, un lenguaje propio de programación, similar en muchos aspectos al Basic, que se denomina EASI Modeling, accesible desde el menú Tools de la barra del programa. En este lenguaje se pueden escribir macros utilizando una sintaxis sencilla. En primer lugar es necesario indicar sobre qué archivo se va a aplicar el modelo (Input File).
- Menu >> Tools >> Easy Modelling
Éste es el conjunto estándar de operaciones aritméticas disponibles en las expresiones de la modelación:

Cada banda de ese archivo se identifica en el programa por un símbolo (%) seguido del número de canal. Para realizar una operación con los ND de los píxeles de una banda basta incluir en esa fórmula el identificador %X, siendo X la banda de interés. Por ejemplo, para dividir los ND de los píxeles almacenados en el canal 1 y el 2 de un archivo, salvando el resultado en el canal 5, se introduciría: %5=%1/%2. Conviene tener claro que el resultado debe enviarse a un canal vacío; de lo contrario, se estarían sobrescribiendo bandas con información de interés. Otro tema importante es que el resultado de la fórmula tiene que enviarse a un canal con la resolución apropiada. Por ejemplo, si dividimos dos bandas y enviamos el resultado a un canal de 8 bits, probablemente no veremos casi nada como resultado, ya que un canal de 8 bits no admite decimales y, por tanto, el resultado se redondea al entero más cercano perdiéndose la mayor parte de los valores resultantes. En consecuencia, antes de abordar cualquier proceso, habrá que crear bandas vacías sobre el archivo que queramos utilizar. Estas bandas serán de 8, 16 ó 32 bits dependiendo de lo que se quiera almacenar.
Paso 4.1: Procesamiento - Crear umbral para la discriminación de nubes
- Adicionar un nuevo canal Raster de 32bits
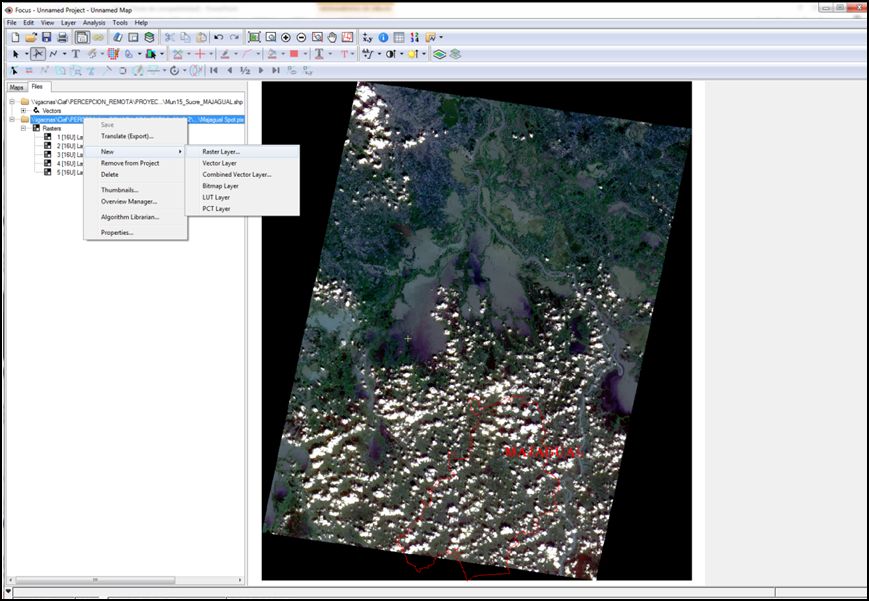
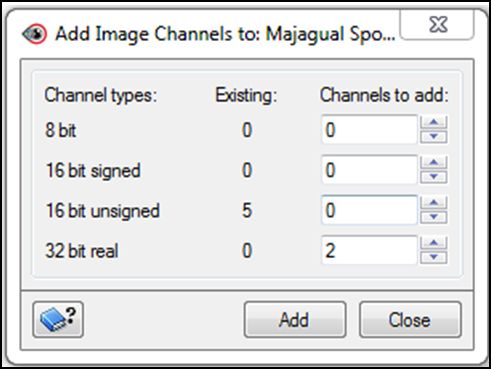
Apoyándonos en la respuesta espectral de las coberturas nubosas en las diferentes longitudes de onda de las bandas de la imagen SPOT, esta característica permite crear un umbral para la exclusión de nubes y sombras de acuerdo a la geometría de iluminación. De esta manera desarrollamos un algoritmo para discriminación del áreas cubiertas por nubes bajo el módulo de programación “easy modeling” contenido en el programa PCI Geomatica 2013.
Dicha descripción se puede observar a continuación:
%6=0
if %3>6400 then
%6=255
endif
%6=0
if %1>3500 then
%6=255
else
if %2>3500 then
%6=255
endif
endif
Su visualización dentro del módulo “easy modeling”:
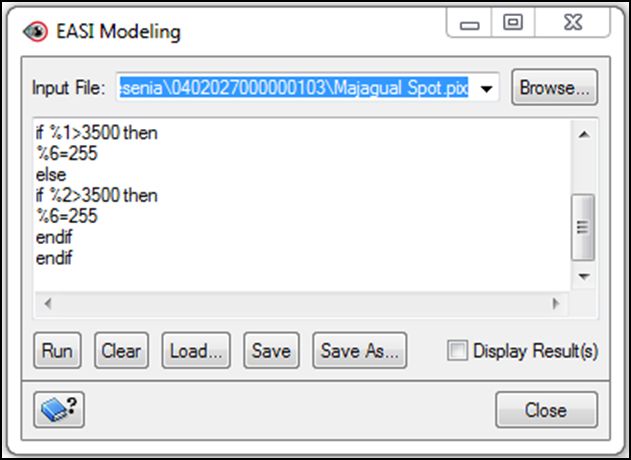
Nota: Cabe destacar que estos valores fueron empleados para esta escena SPOT en particular, y que sus resultados pueden variar o ser sensibles dependiendo de algunos factores como: geometría de iluminación, tipo de sensor, hora de la tomas entre otros.
- El resultado final visto como seudocolor:

Una comparación más detallada se puede apreciar en la siguiente figura :

Paso 4.2: Procesamiento - Creación de polígonos
Una vez creada la máscara en PCI Geomatica 2013, exportamos el canal a un formato raster .tiff con la finalidad de realizar un procedimiento de reclasificación en ArcMap.
- Exportar el canal creado como nuevo archivo .tiff desde el comando TRANSLATE de FOCUS:
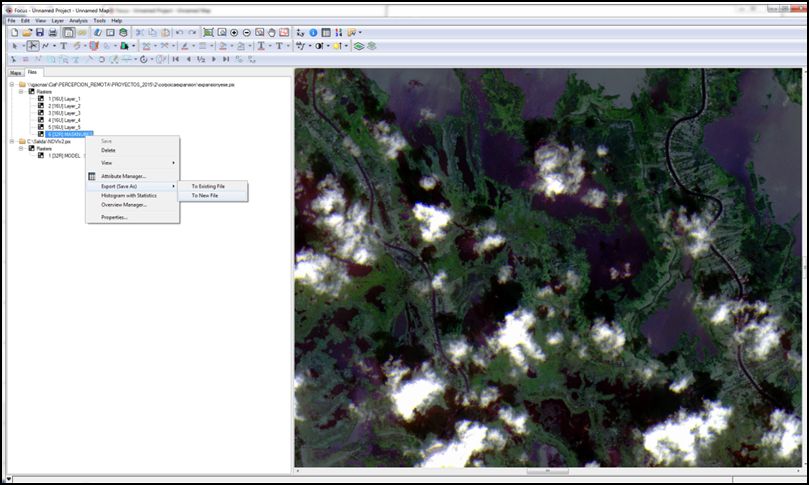
A continuación abrimos el software ArcMap 10.2 e importamos la imagen de la máscara. Posteriormente accedemos a la caja de heramienta en donde se encuentran alojados los módulos de procesamiento y anális espacial “Toolbox”:
- Buscar en Toolbox, la herramienta Reclassify
- ArcToolboox >> Spatial Analyst Tools >> Reclass >> Reclassify
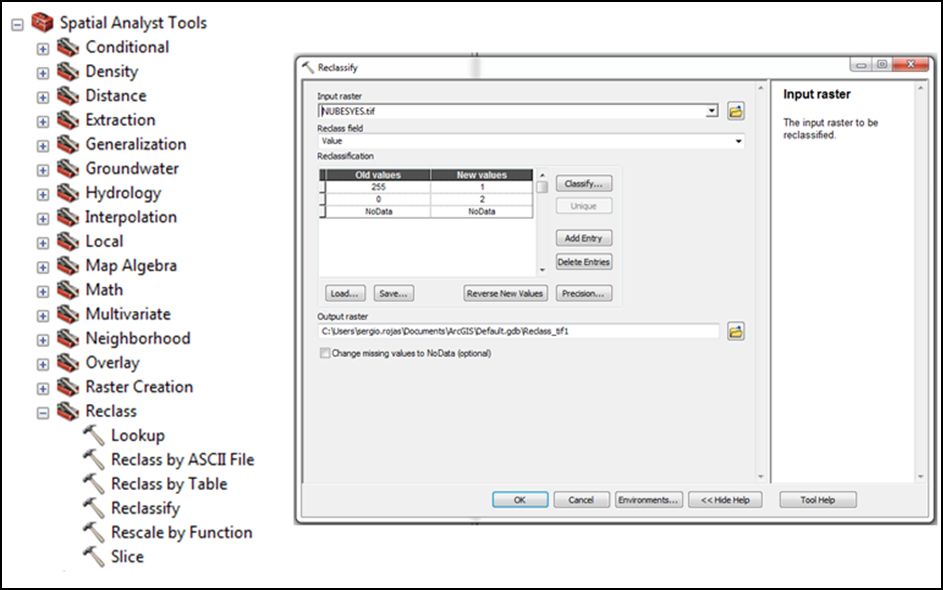
Input Raster: la imagen tiff de máscara de nubes. Creamos dos clases o categorías (Nubes y no nubes). Lo demás por defecto. Y damos OK.
Conversion de Raster a Polígono
Una vez reclasificada la imagen, procedemos a convertir nuestra capa Raster en una capa Vectorial de formato shape (.shp).
Para ello buscamos nuevamente en nuestro módulo de herramientas ToolBox el algoritmo Raster to Polygon:
- ArcToolboox >> Conversion Tools >> From Raster>> Raster to Polygon
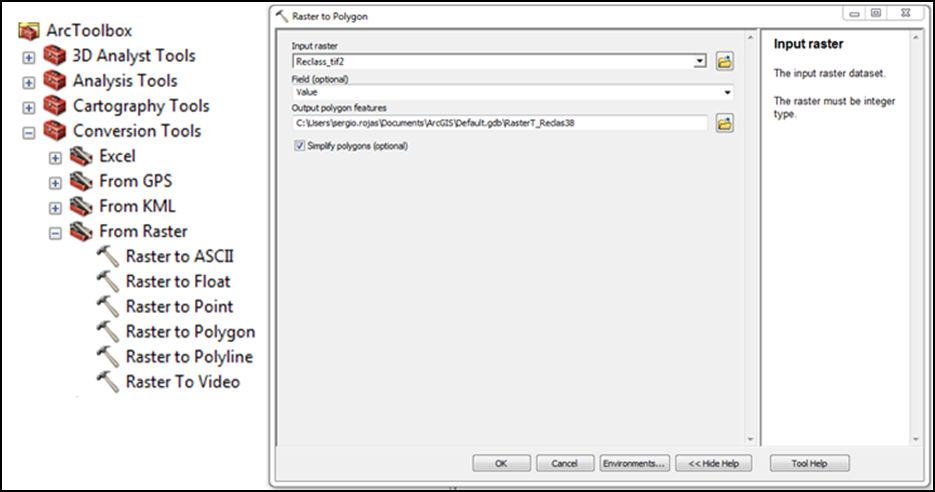
- Input Raster: la imagen tiff reclasificada. Lo demás por defecto.OK

Paso 4.3: Visualización
Con el fin de mejorar el realce visual, procedemos a realizar un visualizado en categorías de un único valor de GRIDCODE.
- Click derecho en la capa vector recién creada >> Propierties…
- Layer Properties >> Symbology
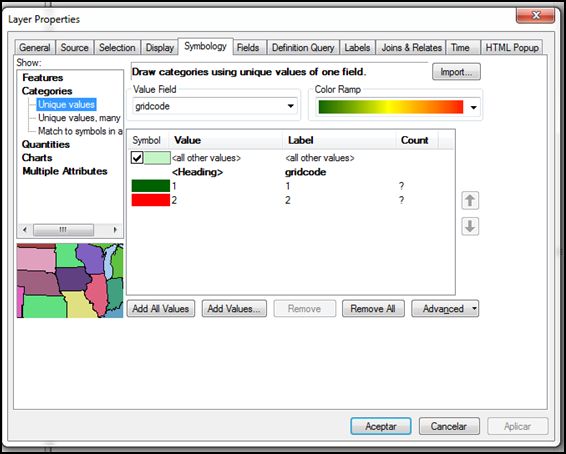
- Value Field: gridcode. Click en Add All Value. Aceptar
El resultado final nos muestra una salida gráfica con la visualización total de nubes para la escena seleccionada:
Nota: Para la extracción de polígonos, se tendrá en cuenta que para escalas de trabajo a 1:25.000, la unidad mínima cartografiable es de 1 Ha. De este modo, una vez extraigamos los polígonos debemos de asegurarnos que los polígonos son del tamaño adecuado. Para ello procederemos con las siguientes herramientas:
Reclasify
Raster to polygon
Eliminate, Majority
Paso 4.4: Eliminación de áreas mínimas
Una vez que tengamos el vectorial, crearemos en su tabla de atributos una columna para calcular el área en hectáreas, de este modo seleccionaremos los polígonos menos a 1 Ha, para eliminarlos con la siguientes herramientas:
- ArcTools Box >> Data Management Tools >> Generalization >> Eliminate
- ArcTools Box >> Spatial Analyst Tools >> Generalization >> Majority Filter
Fase 2: Procesamiento de datos
Paso 5: Procesamiento - Obtención de índices espectrales
La segunda parte del modelo CAIN, consiste en obtener los índices espectrales definidos en la teoría para la delimitación de cuerpos de agua. Una vez realizado el pre-procesamiento, podemos comenzar a generar los diferentes índices. A pesar de valorar diferentes índices espectrales (NDWI-NDVI-ICEDEX - MNDWI), utilizaremos para este ejemplo uno de los mejores índices según el análisis de sensibilidad para la extracción de cuerpos de agua, el NDVI:
NDVI = (Infrarrojo - Rojo) / (Infrarrojo+ Rojo)
La implementación y obtención de estos índices espectrales dentro del modelo CAIN, puede verse a continuación:
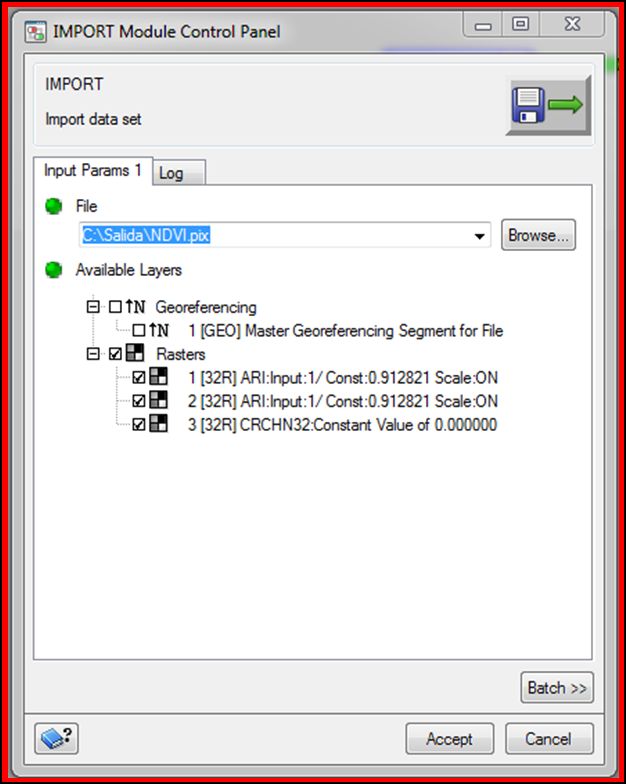
De este modo el primer paso consiste en crear un nuevo módulo IMPORT en el espacio de trabajo, igual que en el paso 1.
Se seleccionan los canales de origen de donde se extraerán los índices espectrales a generar:
Posteriormente adicionaremos un nuevo módulo llamado MODEL desde la librería de algoritmos, el cual permitirá transcribir la fórmula de generación del índice espectral:
- Menú>> View >> Module Librarian
- Find >>Escribir MODEL>> Arrastra al espacio de trabajo:
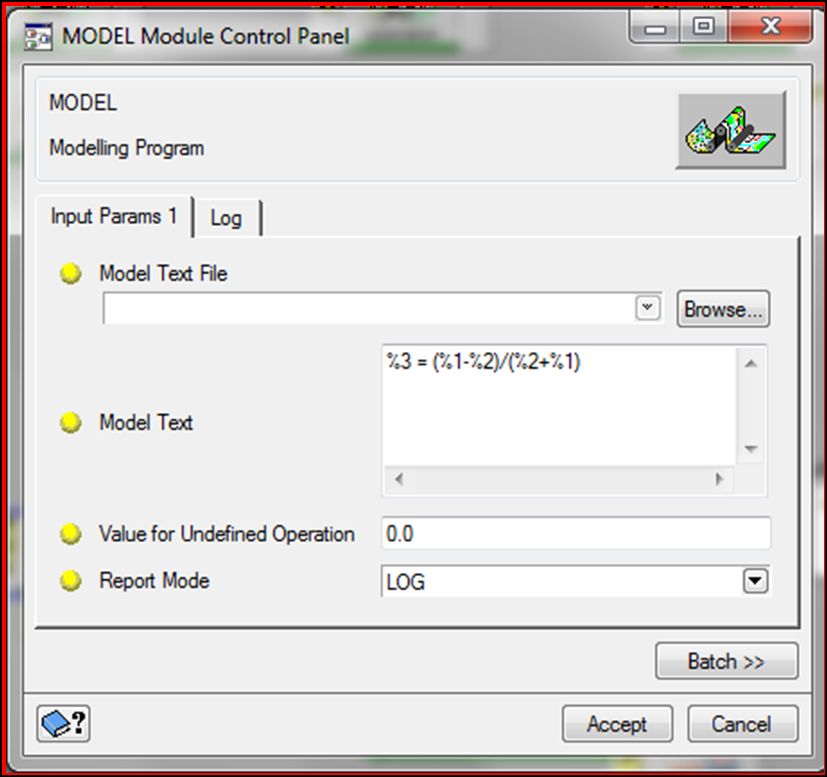
Seguidamente agregaremos un módulo que permite visulalizar el proceso (VIEWER), además de un módulo que permita salvar y esportar los resultados:
- Click derecho >> Commom Modules >> Viewer
- Click derecho >> Commom Modules >>Export

De esta manera una vez esté corriendo el proceso, podremos visualizar los resultados generados:
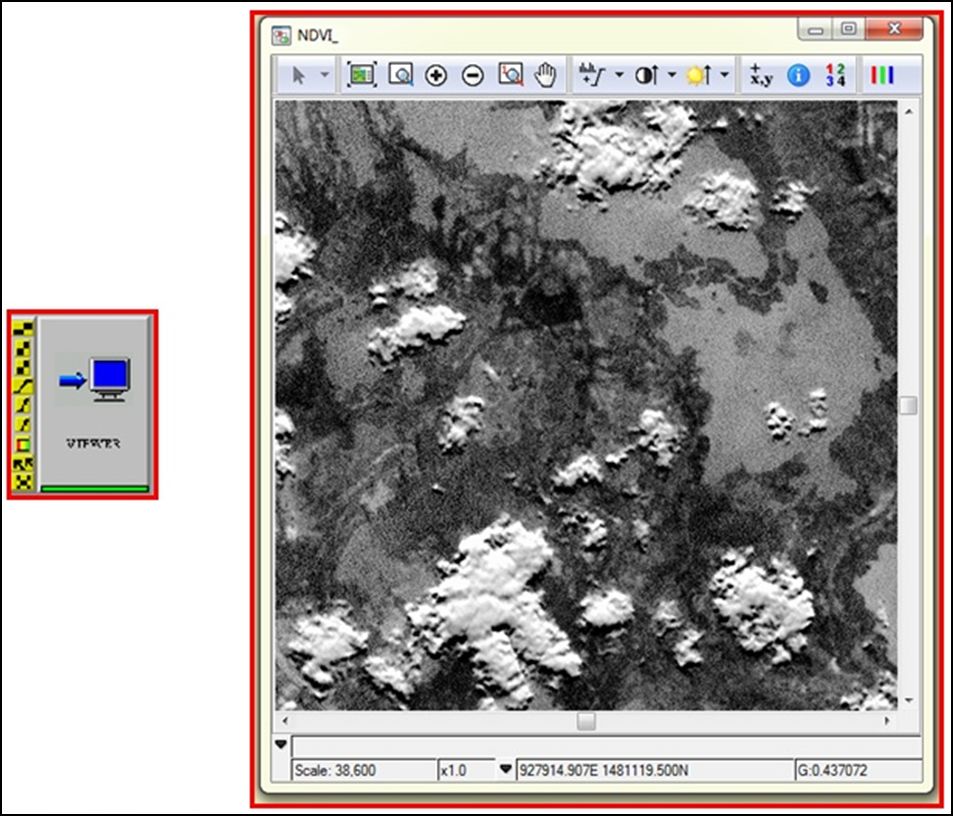
Adicionalmente podremos crear un modelo para cada uno de los índices que queremos evaluar:
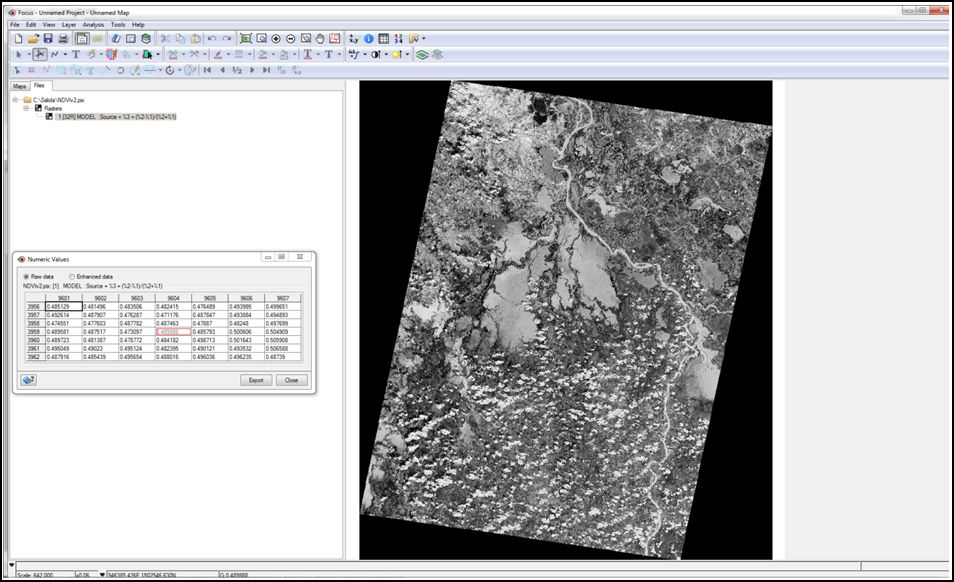
NDWI (Fuente: McFeeters 2007):
NDWI = (Verde - Infrarojo) / (Verde + Infrarrojo)
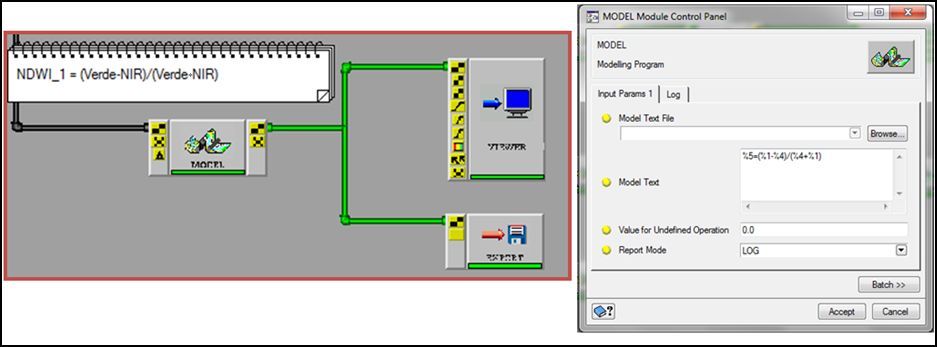
Una vista final del modelo CAIN (Correción Atmosférica y Obtención de Índices Espectrales para la Identificación de Cuerpos de Agua) se puede apreciar a continuación:
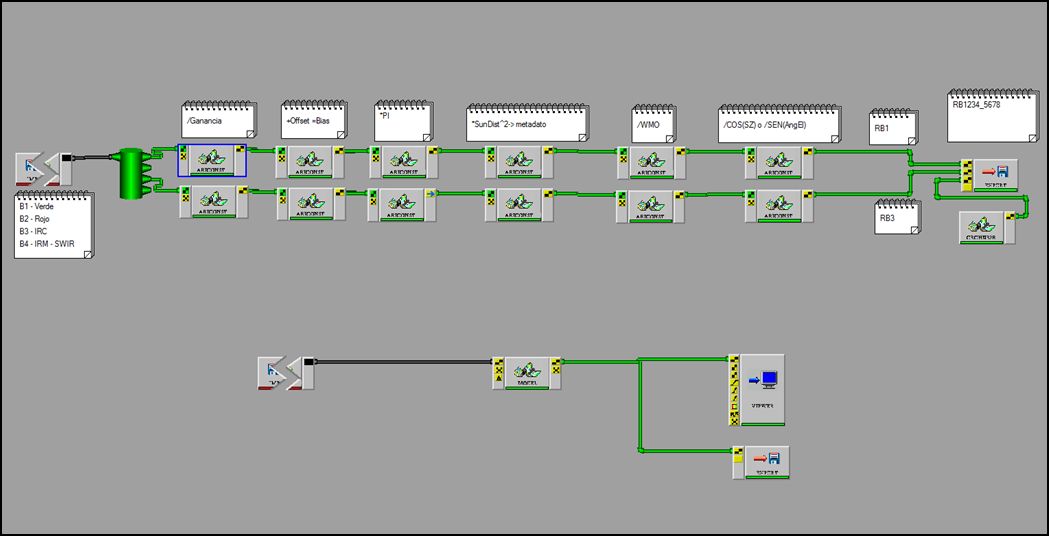
Vista final del modelo CAIN. (Corrección Atmosférica y Obtención de Índices Espectrales para la Identificación de Cuerpos de Agua).
A partir del NDVI u otros índices espectrales se generan imágenes donde se resaltan los cuerpos de agua. La efectividad de la separabilidad de cada índice se evalúa con el índice o la relación discriminante de Fisher.
Paso 6: Relación Discriminante de Fisher (FDR)
La Relación Discriminante de Fisher (FDR) cuantifica el grado de separabilidad entre coberturas de muestra y se basa solo en los parámetros estadísticos de la media μ y la varianza σ. Las coberturas con más alto FDR son más discriminantes que aquellas con menor índice.

Donde 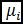 es el valor de la media de los cuerpos de agua,
es el valor de la media de los cuerpos de agua, 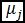 es el valor de la media de los no cuerpos de agua. De igual modo
es el valor de la media de los no cuerpos de agua. De igual modo 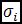 es el valor de la varianza de los cuerpos de agua y
es el valor de la varianza de los cuerpos de agua y 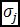 es el valor de la varianza de los no cuerpos de agua. Como ejemplo, se muestran las tablas resumen y el valor de la relación discriminante de Fisher para una imagen Rapideye del departamento del cesar para época Niña:
es el valor de la varianza de los no cuerpos de agua. Como ejemplo, se muestran las tablas resumen y el valor de la relación discriminante de Fisher para una imagen Rapideye del departamento del cesar para época Niña:

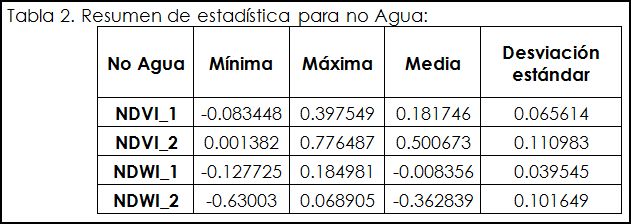
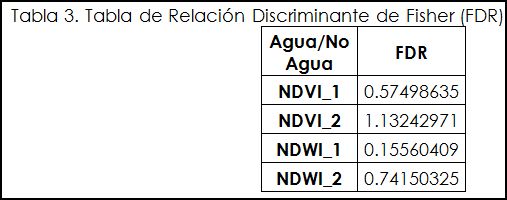
Se puede apreciar que el Índice Espectral con mejor desempeño para esta zona, empleando imágenes RAPYDEYE, fue el NDVI_2 en la discriminación de cuerpos de agua. De este modo, usando el Índice Espectral NDVI_2 para la discriminación estos cuerpos de agua se interpretan y digitalizan visualmente usando la herramienta Editor de ArcMap. Una vez teniendo el vectorial, crearemos en su tabla de atributos una columna para calcular el área en hectáreas, de este modo seleccionaremos los polígonos inferiores a 1 Ha, para eliminarlos con las siguientes herramientas:
- ArcTools Box >> Data Management Tools >> Generalization >> Eliminate
- ArcTools Box >> Spatial Analyst Tools >> Generalization >> Majority Filter
Finalmente se suavizan los polígonos resultantes con la herramienta (Smooth Polygon). (cf. paso 4.3)
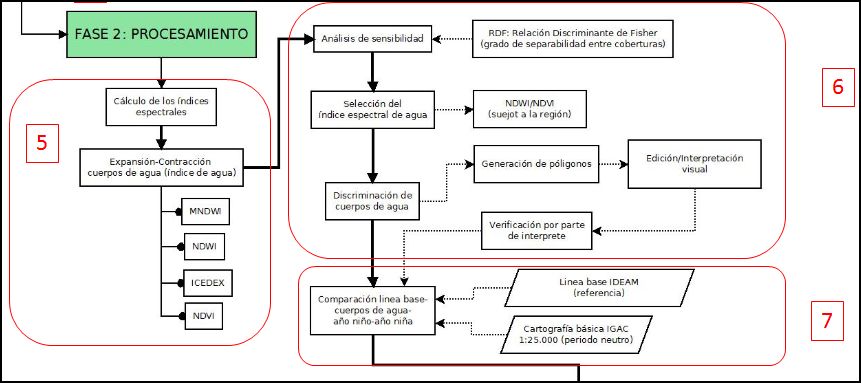
Paso 7: Extracción de los elementos de análisis / Comparación línea base - cuerpo de agua - año niño-año niña
Después de depurar todos los cuerpos del vectorial de la imagen estos se comparan con la cartografía base oficial a escala 1:25.000 del año neutro y con el fin alcanzar los productos para el análisis de dinámica de agua, tendremos que tener en cuenta varios, que serán generados a partir de los insumos generados en el procesamiento (nubes y lámina de agua de la imagen). Los elementos que necesitamos obtener para realizar un óptimo análisis son básicamente el área efectiva de análisis de la imagen y de la línea de agua cartografía básica a comparar, así como los principales componentes de expansión, contracción y desecación. Para ello, construiremos paso a paso un modelo de desarrollo en ModelBuilder del software ArcGIS, con el fin de automatizar los procesos.
- En primer lugar, abra la interfaz de ArcMap de ArcGIS, cargaremos en el visor los datos iniciales que intervendrán en el modelo municipio, área de a escena, las nubes, el água extraída del procesamiento de la imagen y la cartografía básica de cuerpos de agua (IGAC).
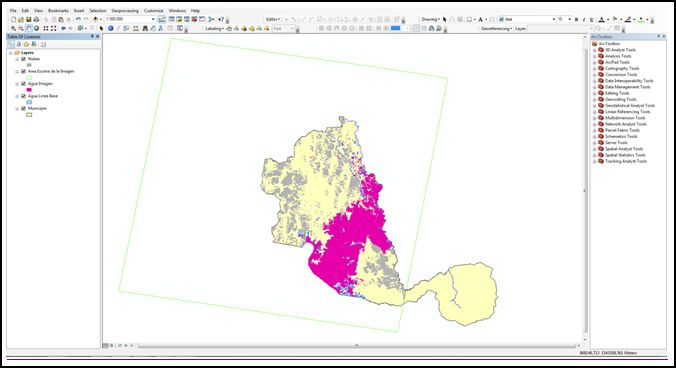
- Una vez teniendo los datos desplegados abriremos la aplicación de ModelBuilder, encontrando esta opción en la parte superior de herramientas, en el siguiente icono.

Paso 7.1: Primera parte del modelo – Área efectiva de estudio
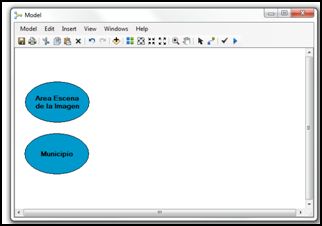
- Dado que el área de la escena no abarca totalmente el municipio, debemos de realizar un corte para poder obtener cuánta información en el área del municipio se ve cubierta por la imagen; para obtener el área efectiva de la imagen con respecto al municipio. Para ello utilizaremos la herramienta Clip, la buscaremos en Arctoolbox >> Analysis Tools >> Extract >> Clip (seleccionamos la herramienta y la arrastramos hasta el modelo).
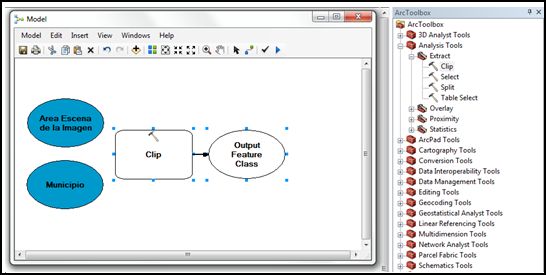
- Con la herramienta Connect
 uniremos pinchando en el insumo y arrastrando la flecha de conexión hasta la herramienta y dando la función para cada dato:
uniremos pinchando en el insumo y arrastrando la flecha de conexión hasta la herramienta y dando la función para cada dato:
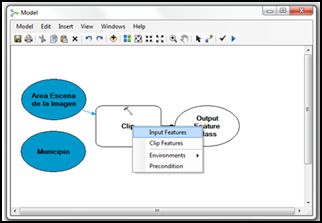
- Una vez se conectan los datos de entrada, el modelo se vuelve activo, de color amarillo para el proceso y de color verde para el producto del proceso. Es recomendable que cambiemos el nombre y pongamos una ubicación adecuada al producto de este proceso, haciendo doble click sobre el óvalo de color verde y cumplimentando la ventana de éste.
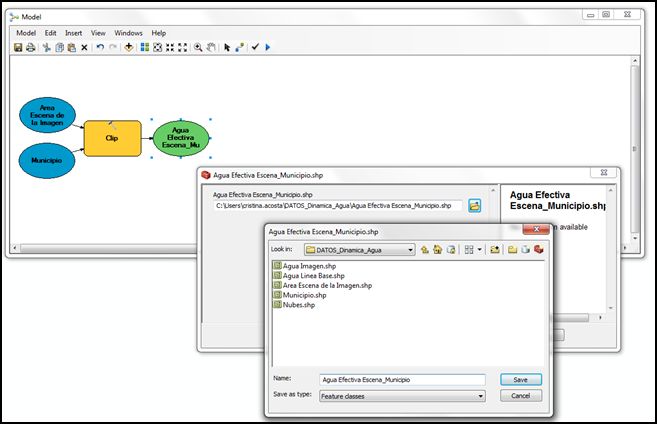
De este modo se irá completando el modelo, es decir, añadiendo datos de entrada. Pueden ser los de inicio (azules) o pueden ser los ya creados como productos (verdes) y enlazando procesos. Así mismo si queremos saber si el modelo se encuentra correctamente construido, podemos validarlo en cualquier momento haciendo click en Validate .
- Lo siguiente será obtener el área efectiva total del área de estudio, es decir, al área ya obtenida en este proceso realizado anteriormente, eliminando las zonas de nubosidad. Para ello usaremos la herramienta Erase, que se encuentra en Arctoolbox >> Analysis Tools >> Overlay >> Erase. Usaremos “Area Efectiva Escena-Municipio” como Input Features y “Nubes” como Erase Features.
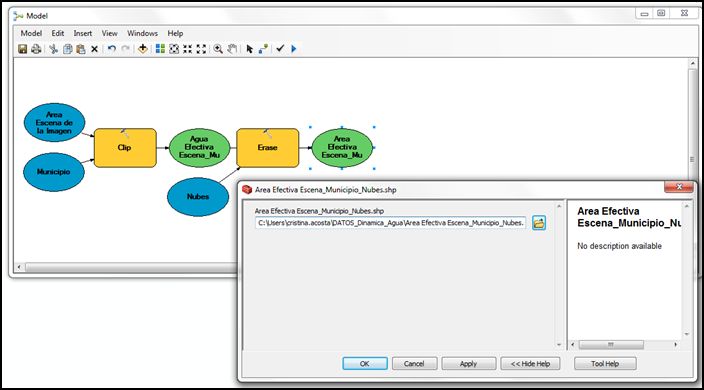
Paso 7.2: Segunda parte del modelo – Áreas efectivas de agua
Con el área efectiva real del municipio crearemos las áreas efectivas de la Cartografía Base de Agua y del agua de la imagen (como verificación); éstos serán los productos necesarios para poder calcular la Expansión, Contracción y Desecación.
Para ésto construiremos dos procesos paralelos con la herramienta Clip (anteriormente vista) con el archivo “Área Efectiva Escena-Municipio-Nubes” como la forma de corte Clip Features; uno con la Cartografía Base de Agua y otro con el agua extraída de la imagen, como Input Features.
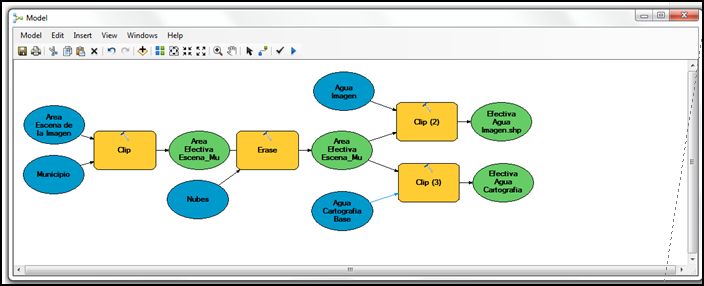
Dado que más adelante se requerirá cargar en la tabla de contenidos estos productos de aguas efectivas, podemos indicar qué archivos/productos queremos que se visualicen al realizarse el proceso, pinchando en el botón derecho y pulsando la opción Add to Display.
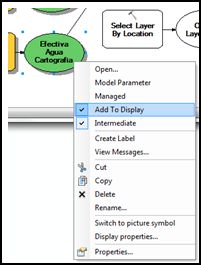
Paso 7.3: Tercer parte del modelo – Expansión
En este paso generaremos como producto un archivo que contenga los polígonos de expansión del agua, es decir aquellas zonas en las que en el agua de la Cartografía Base de Agua no existía, pero en la fecha de la imagen sí.
De este modo, usaremos los polígonos de aguas efectivas (producidos en la segunda parte), de la imagen y de la cartografía básica de cuerpos de agua. Para hallar el área de expansión utilizaremos como línea el agua de la imagen, y como área a borrar el agua de la superficie abarcada por la cartografía básica de cuerpos de agua, para que queden así los polígonos sobresalientes. A este archivo producto actívele también la opción de visualizarlo al correr el proceso.
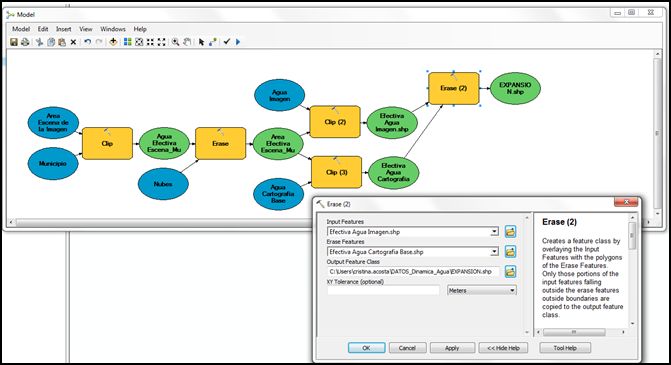
Paso 7.4: Cuarta parte del modelo –Desecación
Contemplaremos la desecación como aquellos cuerpos de agua que aparecen en la cartografía básica de cuerpos de agua, pero que de los que no se encuentra evidencia en el agua extraída de la imagen.
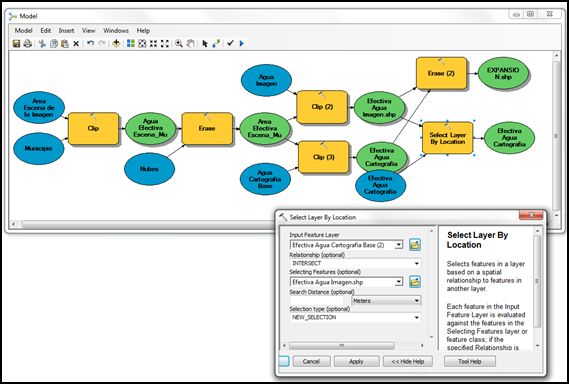
- En primer lugar debemos seleccionar aquellos cuerpos de agua de la cartografía básica que intersectan con los polígonos de agua del procesamiento digital de la imagen utilizada. Esto lo lograremos cruzando dichos datos a partir de una selección por localización, herramienta que encontraremos en Arctoolbox >> Data Management Tools >> Layers and Table Views >> Select Layer By Location.
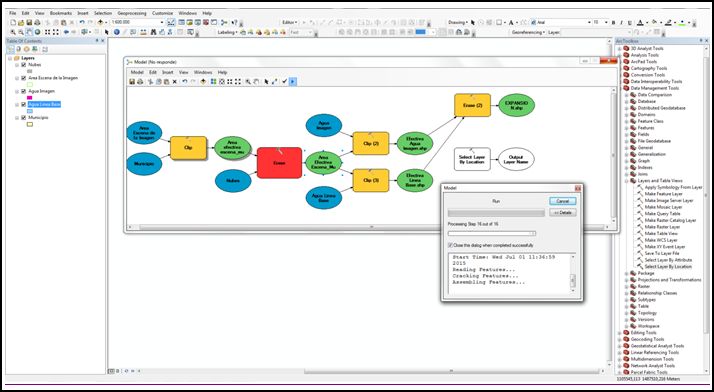
- Antes de seguir construyendo nuestro modelo, dado que para esta parte es necesario que los datos de entrada sean tangibles y tengan la tabla de atributos creada, se requiere correr el modelo en el botón Run
 .
.
- Ahora si podremos conectar de forma adecuada la herramienta de selección por localización, añadiendo previamente el archivo de la tabla de contenidos “Efectiva Agua Cartografía Base” (que fue cargada automáticamente como efecto de la activación de que fuera añadido a la visualización, Add to display), pondremos ésta como Input Feature Layer dado que es la capa que queremos seleccionar; y el archivo producto en el modelo “Efectiva Agua Imagen” como Selecting Features. Además tendremos que indicar que la relación entre ambos archivos será de intersección, como una nueva selección.
- Ahora para conseguir que los cuerpos de agua de la cartografía básica no intersequen con el agua de la imagen, debemos añadir el proceso de Select Layer By Attribute ubicada en Arctoolbox >> Data Management Tools >> Layers and Table Views >> Select Layer By Attribute (este proceso se pudo haber realizado en la selección por localización, indicando no nueva selección, sino esta misma opción de invertir la selección, pero en la versión del software no funciona de la manera esperada). Además tendremos en cuenta el tipo de selección, Selecction Type como Switch Selection, es decir invertir la selección.
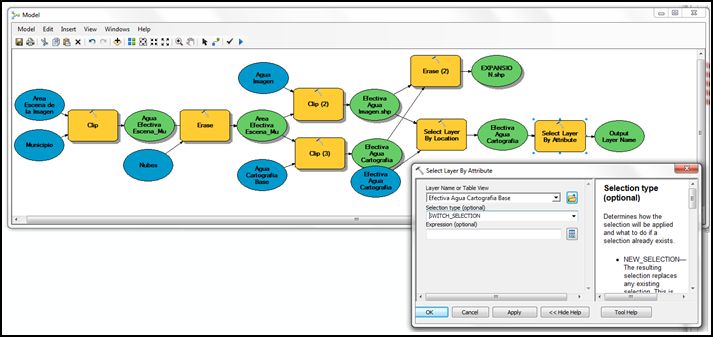
- En este punto del modelo para obtener los polígonos respectivos a la desecación, ya solo falta extraer los datos seleccionados, gracias a los dos procesos anteriores; para ésto utilizaremos la herramienta Select, emplazado en Arctoolbox >> Analysis Tools >> Extract >> Select, dando nombre y ubicación de salida al producto final de Desecación; además pulsaremos el botón derecho sobre el producto para indicar que lo cargue en la visualización después del proceso.
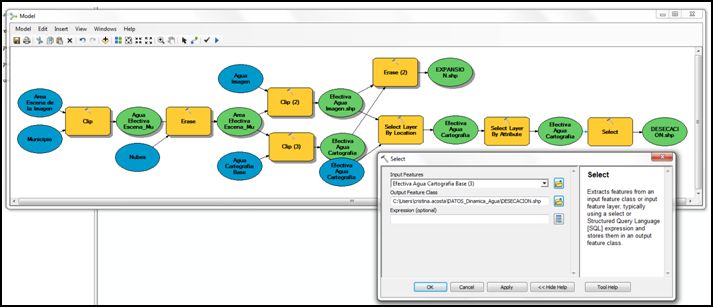
Paso 7.5: Quinta parte del modelo – Contracción
Denominamos contracción a los cuerpos de agua que se redujeron, es decir superficies de agua que existían en la cartografía básica y en las que se evidencia una disminución con respecto al espejo de agua separado en las imágenes satelitales procesadas.
Comenzaremos realizando de nuevo un Erase con los datos de aguas efectivas, en esta ocasión usando la cartografía básica de cuerpos de agua como Input Features, y el agua de la imagen como Erase Features; con el fin de obtener los polígonos de agua que se vieron reducidos, eliminando de los polígonos completos del área de agua de la imagen, de las zonas en la que los cuerpos de agua de la cartografía básica que se mantuvieron estables. A este producto lo denominaremos Contracción, y activaremos la opción para que sea cargado al correr el modelo.
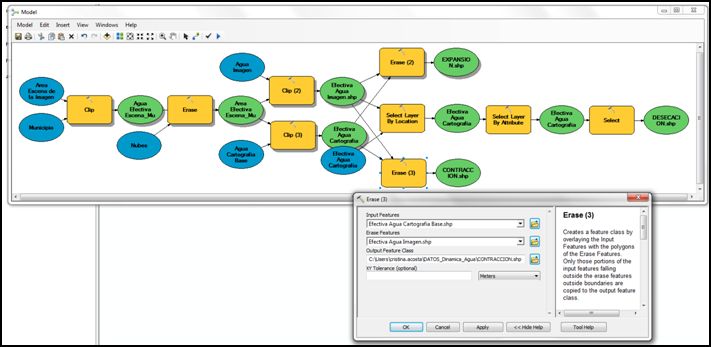
- Por último, quedaría un paso para obtener las zonas de contracción, dado que con solo el paso anterior aparecen también las zonas de desecación, y no podemos duplicar este valor. Para ello, debemos volver a correr el modelo
 , obteniendo así datos perceptibles con su pertinente tabla de atributos para realizar la selección.
, obteniendo así datos perceptibles con su pertinente tabla de atributos para realizar la selección.
Luego de asegurarnos haber corrido el modelo haremos una selección por localización, entre los polígonos de la contracción y la desecación, con el fin de poder luego eliminarlos. Para esta selección, arrastraremos el dato de entrada recién generado de Contracción; éste será el Input Features Layer en la selección, combinado con la desecación como Selecting Features.
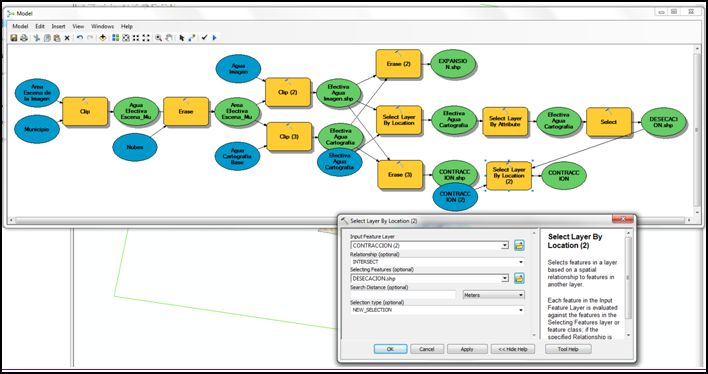
- Ahora que en este paso del modelo tenemos seleccionados en el archivo de contracción las áreas de desecación, eliminaremos estos registros con la herramienta Delete Features, encontrada en Arctoolbox >> Data Management Toods >> Features >> Delete Features.
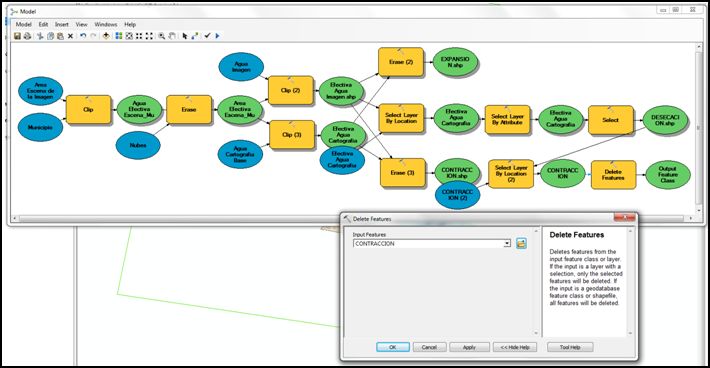
Paso 7.6: Sexta parte del modelo – Cálculo de áreas para análisis
Es fundamental poder cuantificar los diferentes polígonos de expansión, desecación y contracción, para poder dar respuesta del comportamiento de la dinámica de agua.
De este modo añadiremos a todos los productos a los que les sea necesario una línea de proceso para calcular en la tabla de cada archivo el área en hectáreas. Este proceso puede ser copiado y pegado tantas veces como sea necesario, conectándolo a los archivos que requieran de este desarrollo.
Primero indicaremos el proceso de añadir la columna con la herramienta Add Field, desde Arctoolbox >> Data Management Tools >> Fields >> Add Field. Indicaremos el nombre de la columna “Area_Ha” y estableceremos el Tipo de Campo como Doble (Double).
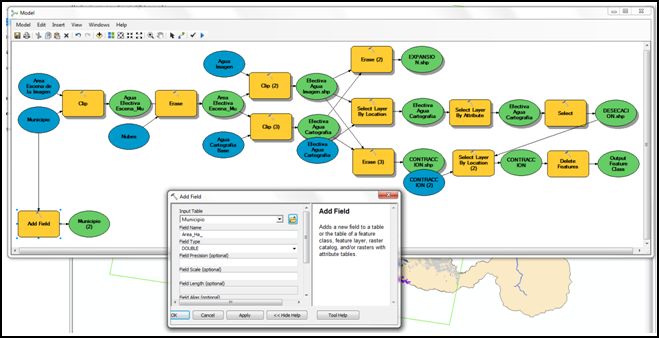
- A este proceso añadiremos el cálculo del campo con la herramienta Calculate Field, que se encuentra en Arctoolbox >> Data Management Tools >> Fields >> Calculate Field; seleccionando en Field Name la columna generada en el paso anterior “Area_Ha” y utilizando el Tipo de Expresión PYTHON escribiremos en la ventana de expresión “!shape.area@hectares!”, como se indica en la siguiente imagen.
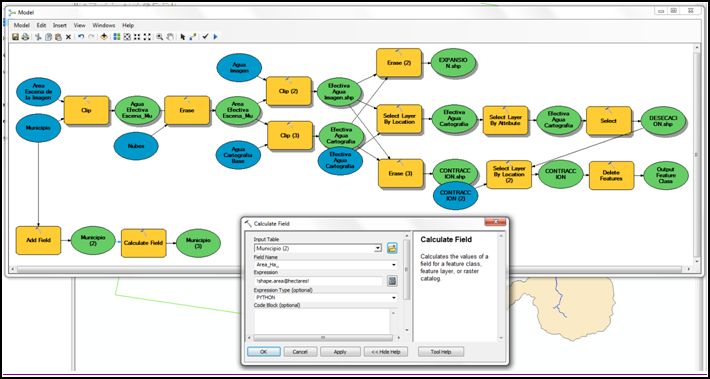
- En el caso presentado calcularemos el área a todos los datos relevantes para el análisis; de esta forma el modelo construido ya puede volver a ser iniciado en el botón Run
 para generar el resto de productos, el modelo completo se muestra de la siguiente manera:
para generar el resto de productos, el modelo completo se muestra de la siguiente manera:
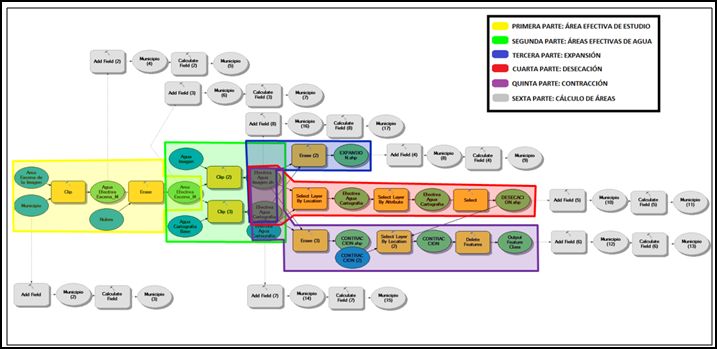
De este modo, también presentamos la vista del producto del modelo de dinámica de cuerpos de agua, en la siguiente figura:
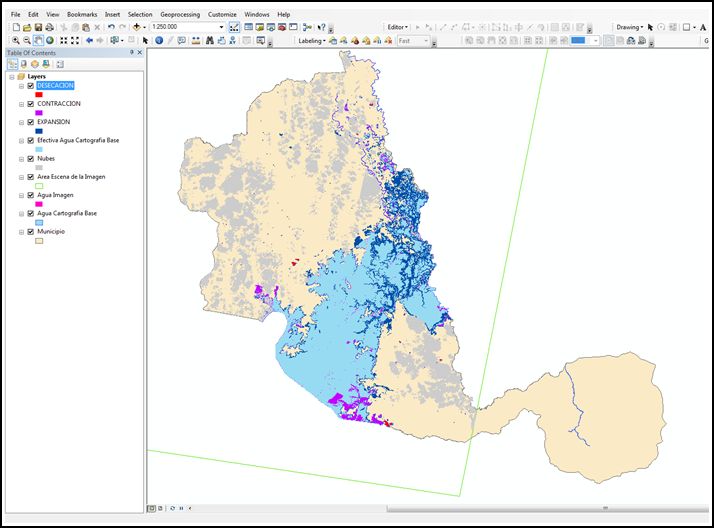
Evaluación
Fase 3: Postprocesamiento
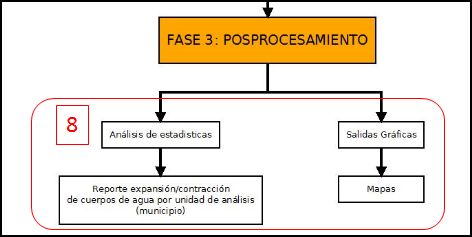
Paso 8: Creación de mapas, salidas gráficas y correlación de resultados
Se elaboraron las geodatabases (GDB) con las capas vector generadas. Guardando así los polígonos de los cuerpos de agua extraídos previamente. Cabe resaltar que no se utilizó la totalidad de la cartografía básica del municipio, sino que el análisis se enfocó en aquellas zonas donde se evidenció presencia de cuerpos de agua. De esta manera se identificaron aquellas zonas donde a nivel municipal se detectó expansión o contracción en los cuerpos de agua.
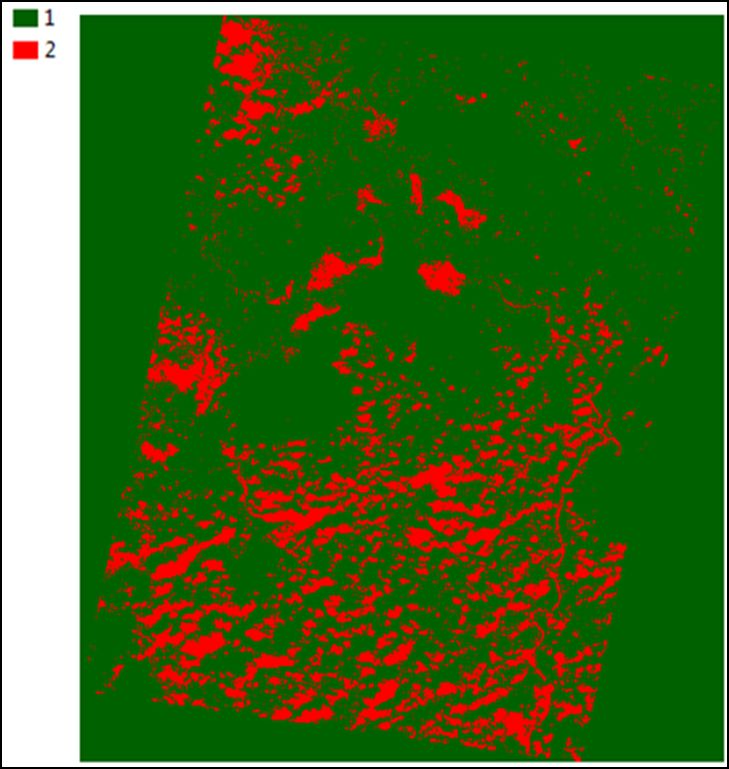
La comparación y correlación de datos se realizó en función de la información suministrada por el cálculo del índice de sequía de Palmer “PDSI”, en donde los valores para los períodos de el Niño sugirieron condiciones de sequía moderada (rango promedio PDSI entre -3.33 y -1.2), mientras que los valores del PDSI promedio para los períodos La Niña sugirieron condiciones de muy húmedo a extremadamente húmedo (rango promedio PDSI entre 2.79 y 4.76). A partir de la comparación de las imágenes se calculó una reducción de los cuerpos de agua de Sopetrán de 80.82Ha (-24.17%) para El Niño, en contraste con el aumento de 171.87Ha (51.4%) del área cubierta por agua para La Niña (cf. figura abajo).
Ejemplo del producto resultante
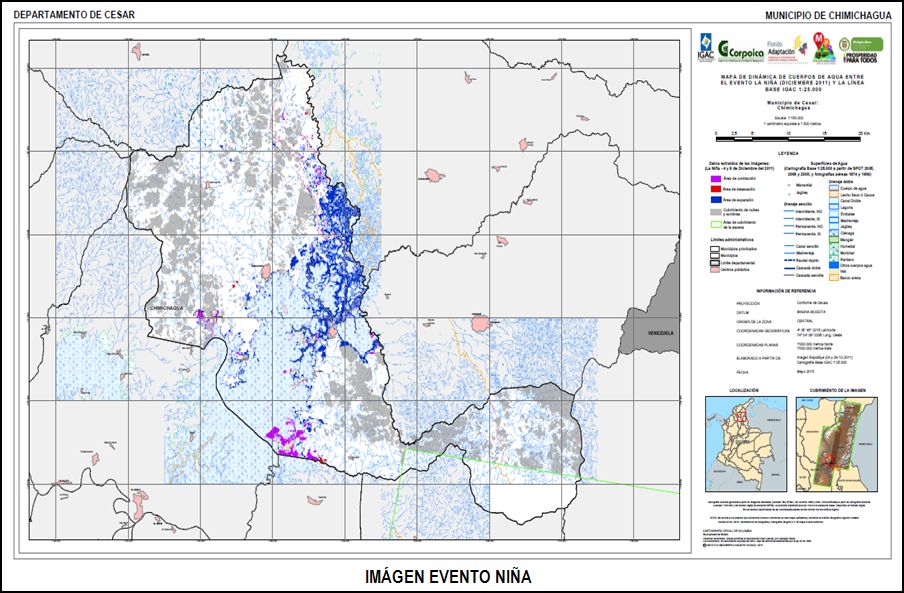
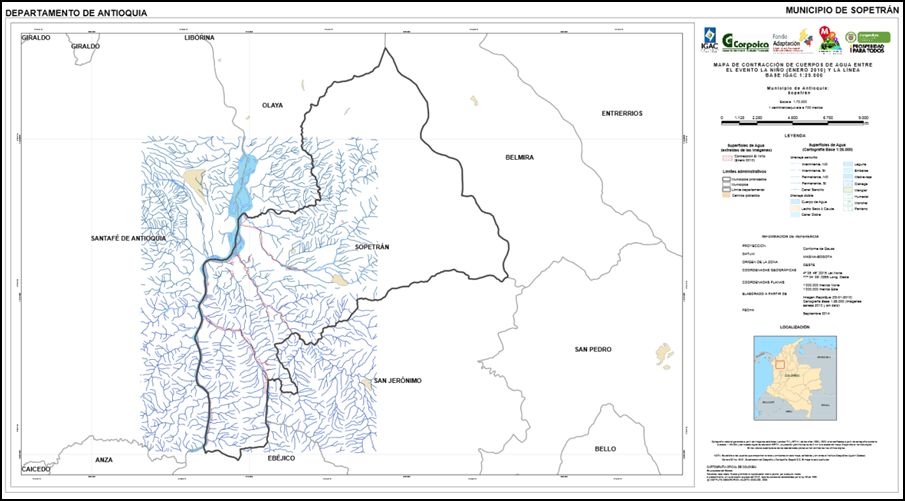
Figura: Expansión de cuerpos de agua, municipio de Chimichagua, departamento de Cesar (Colombia).